

Figues (explication rapide des sommes d’arbres gourmandes): L’invention concerne un procédé de construction de modèles interprétables en développant simultanément un ensemble d’arbres de décision en concurrence les uns avec les autres.
Les progrès récents de l’apprentissage automatique ont conduit à des modèles prédictifs de plus en plus complexes, souvent au détriment de l’interprétabilité. L’interprétabilité est souvent nécessaire, en particulier dans les applications à fort enjeu telles que la prise de décision clinique ; Les modèles interprétables aident à toutes sortes de choses, comme l’identification des erreurs, l’exploitation des connaissances du domaine et la réalisation de prédictions rapides.
Dans cet article de blog, nous aborderons FIGS, qui est une nouvelle façon de monter un fichier modèle interprétable Il prend la forme d’un groupe d’arbres. Les expériences du monde réel et les résultats théoriques montrent que les FIGS peuvent s’adapter efficacement à un large éventail de structures de données, atteignant des performances de pointe dans une multitude de contextes, le tout sans sacrifier l’interprétabilité.
Comment fonctionne la figue ?
Intuitivement, FIGS fonctionne en étendant CART, un algorithme glouton typique du développement d’arbres de décision, pour considérer le développement de somme des arbres ensemble (Voir Figure 1). A chaque itération, la figue peut soit développer un arbre existant qui a déjà démarré, soit démarrer un nouvel arbre ; Il choisit avidement quelle règle minimise le plus la variance totale inexpliquée (ou un autre critère de division). Pour garder les arbres synchronisés les uns avec les autres, chaque arbre est généré pour prédire gueule de bois restant après avoir collecté les prédictions de tous les autres arbres (voir article pour plus de détails).
Les formes sont intuitivement similaires aux approches de cluster telles que l’amplification de gradient/la forêt aléatoire, mais plus important encore, comme tous les arbres sont cultivés pour se concurrencer, le modèle peut s’adapter davantage à la structure sous-jacente des données. Le nombre d’arbres et la taille/forme de chaque arbre apparaissent automatiquement à partir des données plutôt que d’être sélectionnés manuellement.

Graphique 1. Intuition de haut niveau de la façon dont FIGS s’intègre dans un modèle.
Exemple d’utilisation de fichiers FIGS
L’utilisation de FIGS est très simple. Il peut être facilement installé via le package imodels (pip install imodels) et ils peuvent ensuite être utilisés de la même manière que les modèles scikit-learn standard : importez simplement votre classeur ou votre enregistreur et utilisez fit Et predict Méthodes. Vous trouverez ci-dessous un exemple complet de son utilisation dans un exemple d’ensemble de données cliniques dans lequel la cible est le risque de lésion de la colonne cervicale (CSI).
from imodels import FIGSClassifier, get_clean_dataset
from sklearn.model_selection import train_test_split
# prepare data (in this a sample clinical dataset)
X, y, feat_names = get_clean_dataset('csi_pecarn_pred')
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42)
# fit the model
model = FIGSClassifier(max_rules=4) # initialize a model
model.fit(X_train, y_train) # fit model
preds = model.predict(X_test) # discrete predictions: shape is (n_test, 1)
preds_proba = model.predict_proba(X_test) # predicted probabilities: shape is (n_test, n_classes)
# visualize the model
model.plot(feature_names=feat_names, filename='out.svg', dpi=300)
Cela se traduit par un formulaire simple – avec seulement 4 sections (puisque nous avons spécifié que le formulaire ne devait pas avoir plus de 4 sections (max_rules=4). Les prédictions sont faites en déposant un échantillon dans chaque arbre, et résumé Les valeurs d’ajustement au risque ont été obtenues à partir des feuilles résultantes pour chaque arbre. Ce modèle est hautement interprétable, car le clinicien peut désormais (1) faire facilement des prédictions à l’aide des quatre caractéristiques pertinentes et (2) vérifier le modèle pour s’assurer qu’il correspond à son expertise dans le domaine. Notez que cet échantillon est fourni à titre indicatif uniquement et atteint une précision de 84 %.

photo 2. Un modèle simple appris par FIGS pour prédire le risque de blessure à la colonne cervicale.
Si nous voulons un modèle plus flexible, nous pouvons également supprimer la limitation du nombre de règles (changer le code en model = FIGSClassifier()), résultant en un modèle plus grand (voir Fig. 3). Notez que le nombre d’arbres et leur équilibre proviennent de la structure de données – seul le nombre total de bases peut être spécifié.

figue. 3. Un modèle légèrement plus grand que FIGS a appris à prédire le risque de blessure à la colonne cervicale.
Quelle est la performance de FIGS ?
Dans de nombreux cas où l’interprétabilité est souhaitée, comme la modélisation de la base de décision clinique, FIGS est en mesure d’atteindre des performances de pointe. Par exemple, la figure 4 montre différents ensembles de données où FIGS fonctionne parfaitement, en particulier lorsqu’il est limité à l’utilisation de très peu de fractionnements totaux.
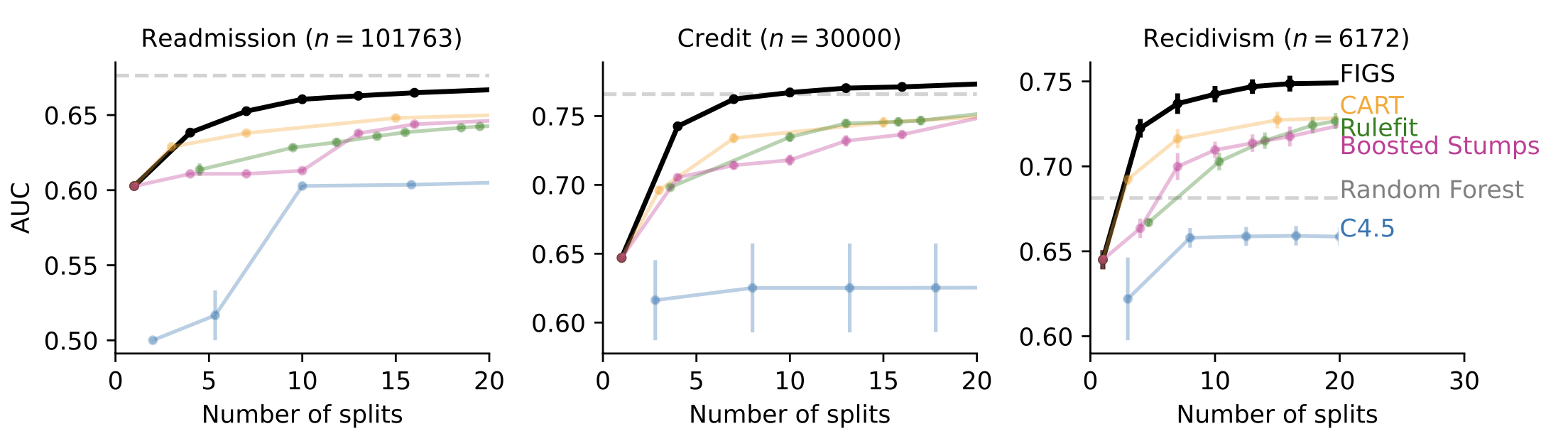
Figure 4. FIGS prédit bien avec très peu de divisions.
Pourquoi les figues fonctionnent-elles bien ?
FIGS est motivé par l’observation que les arbres de décision uniques contiennent souvent des divisions qui itèrent dans différentes branches, ce qui peut se produire lorsqu’il y a une structure additive dans les données. Avoir plusieurs arbres permet d’éviter cela en séparant les ingrédients ajoutés dans des arbres séparés.
Conclusion
En général, la modélisation explicable offre une alternative à la modélisation de boîte noire courante et, dans de nombreux cas, peut offrir d’énormes améliorations en termes d’efficacité et de transparence sans subir de perte de performances.
Cet article est basé sur deux articles : FIGS et G-FIGS – tous les codes sont disponibles via le package imodels. Il s’agit d’un travail conjoint avec Kian Naseri, Abhinah Agarwal, James Duncan, Omar Ronen et Aaron Kornblith.