
Traduire des mots à travers des vidéos non appariées
L’approche la plus courante de la traduction automatique repose sur la modération via un script apparié ou parallèle où chaque phrase dans la langue source est associée à sa traduction dans la langue cible. C’est limitant car nous n’avons pas accès à un tel double ensemble pour la plupart des langues dans le monde. Fait intéressant, les enfants bilingues peuvent apprendre deux langues sans y être exposés en même temps. Au lieu de cela, ils peuvent bénéficier d’une similitude visuelle entre les situations : ce qu’ils remarquent lorsqu’ils entendent “le chien mange” le lundi est similaire à ce qu’ils voient lorsqu’ils entendent “le chien mange” le vendredi.
Dans ce travail, inspiré par des enfants bilingues, nous développons un modèle qui apprend à traduire des mots d’une langue à une autre en utilisant la similitude visuelle des situations dans lesquelles les mots apparaissent. Plus précisément, notre ensemble de données d’entraînement se compose d’ensembles distincts de vidéos racontées dans différentes langues. Ces vidéos partagent des thèmes similaires (par exemple, cuisiner des pâtes ou changer un pneu) ; Par exemple, l’ensemble de données se compose de quelques vidéos sur la façon de cuisiner des nouilles mirwa en coréen et d’un ensemble différent de vidéos sur le même sujet mais en anglais. Notez que les vidéos dans différentes langues ne sont pas jumelé.
Notre modèle tire parti de la similarité visuelle des vidéos en reliant les vidéos à leurs récits correspondants dans un espace d’encastrement commun aux langues. Le modèle est formé en alternant entre des vidéos racontées dans une langue et une dans la seconde. Grâce à cette procédure d’apprentissage, et puisque nous partageons une représentation vidéo entre les deux langues, notre modèle apprend un espace articulaire bilingue visuel qui aligne les mots dans deux langues différentes.
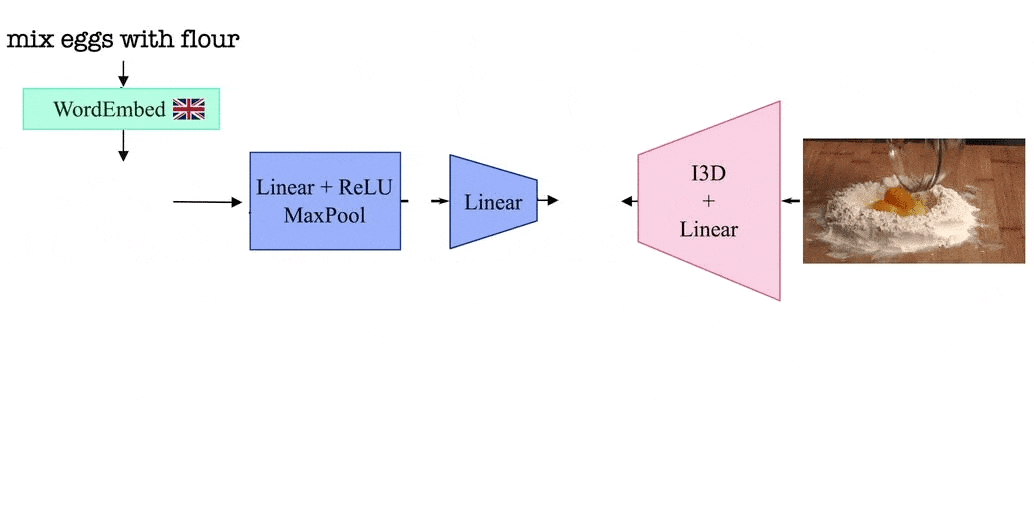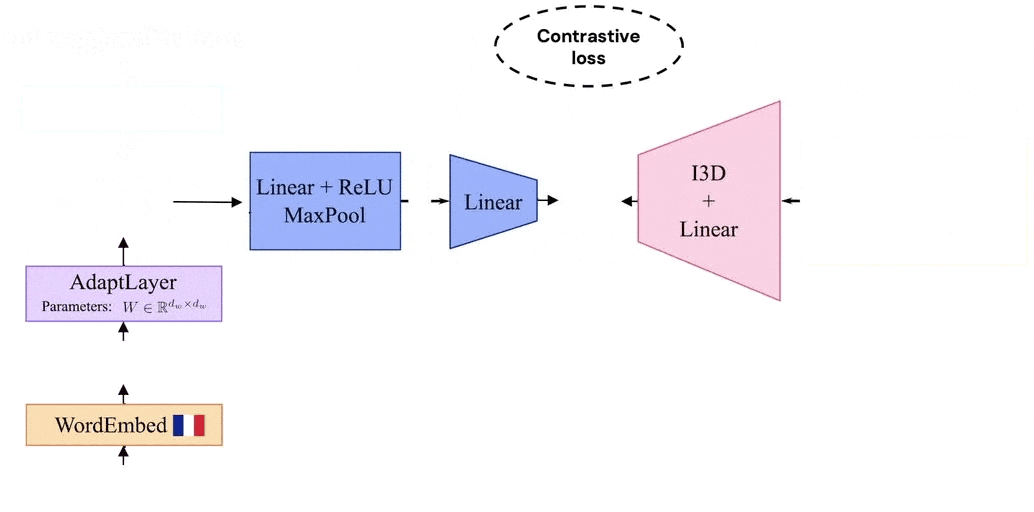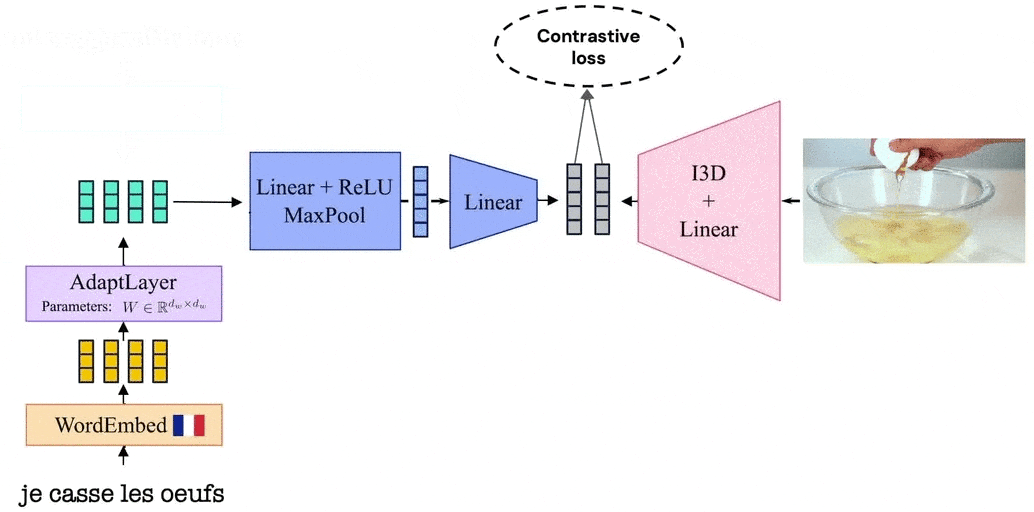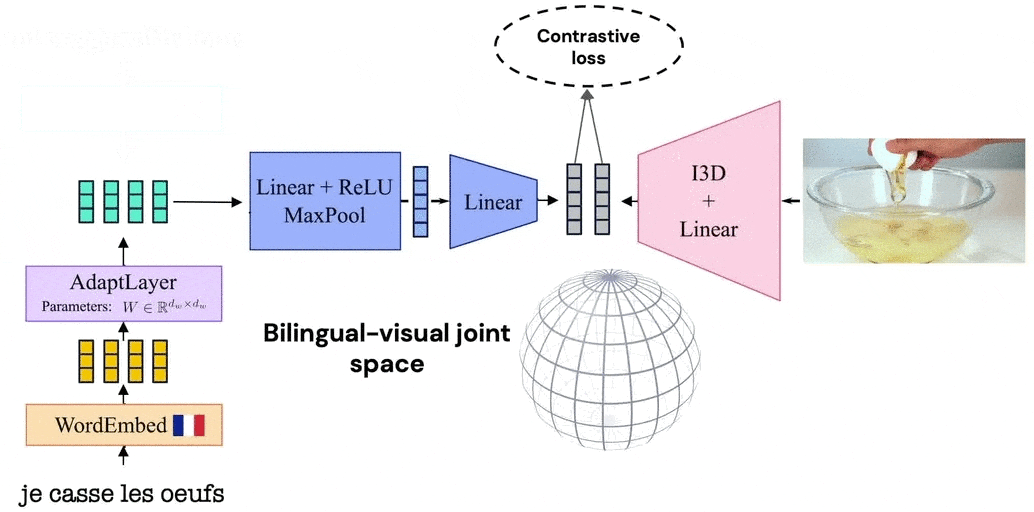
MUVE : Améliorer les méthodes de langage uniquement avec la vision
Nous démontrons que notre méthode, MUVE (Unsupervised Multilingual Visual Embeddings), peut compléter les techniques de traduction existantes qui sont entraînées sur l’ensemble mais n’utilisent pas la vision. Ce faisant, nous montrons que la qualité de la traduction des mots non supervisés s’améliore, notamment dans les situations où les méthodes uniquement linguistiques souffrent le plus, par exemple lorsque : (i) les langues sont très différentes (par exemple l’anglais et le coréen ou l’anglais et japonais), (2) l’organisme principal a des statistiques différentes dans les deux langues, ou (3) une quantité limitée de données de formation est disponible.
Nos résultats indiquent que l’utilisation de données visuelles telles que les vidéos est une voie prometteuse pour améliorer les modèles de traduction bilingue lorsque nous n’avons pas de données associées.