
Fournir un cadre pour la création d’agents IA capables de comprendre les instructions humaines et d’effectuer des actions dans des environnements ouverts
Le comportement humain est remarquablement complexe. Même une simple demande comme “Mettez la balle près de la boîte” nécessite toujours une compréhension approfondie de l’intention et du langage. Il peut être difficile de cerner le sens d’un mot comme “fermer” – mettre la balle à l’intérieur La boîte est peut-être techniquement la plus proche, mais il y a de fortes chances que l’orateur veuille mettre la balle dedans près de boîte. Pour qu’une personne donne suite à une demande, elle doit être en mesure de comprendre et de juger la situation et le contexte environnant.
La plupart des chercheurs dans le domaine de l’intelligence artificielle (IA) pensent désormais qu’il est impossible d’écrire un code informatique capable de capturer les nuances des interactions existantes. Au lieu de cela, les chercheurs modernes en apprentissage automatique (ML) se sont concentrés sur l’apprentissage de ces types d’interactions à partir des données. Pour explorer ces approches basées sur l’apprentissage et construire rapidement des agents capables de comprendre les instructions humaines et d’effectuer des actions en toute sécurité dans des conditions ouvertes, nous avons établi un cadre de recherche dans un environnement de jeu vidéo.
Aujourd’hui, nous publions un article et une série de vidéos, montrant nos premières étapes dans la construction de systèmes d’IA de jeux vidéo capables de comprendre des concepts humains nébuleux – et, à leur tour, peuvent commencer à interagir avec les gens selon leurs propres termes.
Une grande partie des progrès récents dans la formation aux jeux vidéo IA est basée sur l’amélioration du résultat du jeu. Les puissants agents d’IA pour StarCraft et Dota ont été formés en utilisant des gains/pertes clairs calculés par code informatique. Au lieu d’optimiser le résultat du jeu, nous demandons aux gens de proposer des tâches et de juger eux-mêmes des progrès.
En utilisant cette approche, nous avons développé un paradigme de recherche qui nous permet d’améliorer le comportement des agents grâce à des interactions ancrées et ouvertes avec les humains. Bien qu’encore à ses balbutiements, ce modèle crée des agents capables d’écouter, de parler, de poser des questions, de naviguer, de rechercher et de récupérer, de manipuler des objets et d’effectuer de nombreuses autres activités en temps réel.
Cette compilation montre le comportement des agents après des tâches demandées par des participants humains :

apprendre en “théâtre”
Notre cadre commence par des personnes interagissant avec d’autres personnes dans le monde du jeu vidéo. En utilisant l’apprentissage par simulation, nous avons imprégné les agents d’une gamme large mais non raffinée de comportements. Ce “comportement préalable” est nécessaire pour permettre des interactions que les humains peuvent juger. Sans cette étape initiale d’imitation, les facteurs sont complètement aléatoires et presque impossibles à interagir. Un jugement plus humain du comportement de l’agent et l’amélioration de ces jugements par l’apprentissage par renforcement (RL) produisent de meilleurs agents, qui peuvent ensuite être améliorés à nouveau.
Tout d’abord, nous avons créé un monde de jeu vidéo simple basé sur le concept de “salle de jeux” pour enfants. Cet environnement a fourni un environnement sûr pour les humains et les agents pour interagir et a facilité la collecte rapide de grandes quantités de ces données d’interaction. La maison comportait une grande variété de pièces, de meubles et d’objets configurés dans de nouveaux arrangements pour chaque interaction. Nous avons également créé une interface pour interagir.
L’humain et l’agent ont tous deux un avatar dans le jeu qui leur permet de se déplacer et de manipuler l’environnement. Ils peuvent également discuter entre eux en temps réel et collaborer sur des activités, telles que porter et se remettre des objets, construire une tour de blocs ou nettoyer une pièce ensemble. Les participants humains définissent les contextes des interactions en naviguant dans le monde, en fixant des objectifs et en posant des questions aux agents. Au total, le projet a réuni plus de 25 ans d’interactions en temps réel entre des agents et des centaines de participants (humains).
Observez les comportements qui apparaissent
Les clients que nous avons formés sont capables d’un large éventail de tâches, dont certaines n’étaient pas prévues par les chercheurs qui les ont construits. Par exemple, nous avons découvert que ces agents peuvent construire des rangées d’objets en utilisant deux couleurs alternées ou récupérer un objet d’une maison qui est similaire à un autre objet tenu par l’utilisateur.
Ces surprises surviennent parce que le langage permet un ensemble presque infini de tâches et de questions à travers la formation de significations simples. De plus, en tant que chercheurs, nous ne spécifions pas les spécificités du comportement des agents. Au lieu de cela, les centaines d’humains qui s’engagent dans les interactions ont proposé des tâches et des questions au cours de ces interactions.
Construire un cadre pour créer ces clients
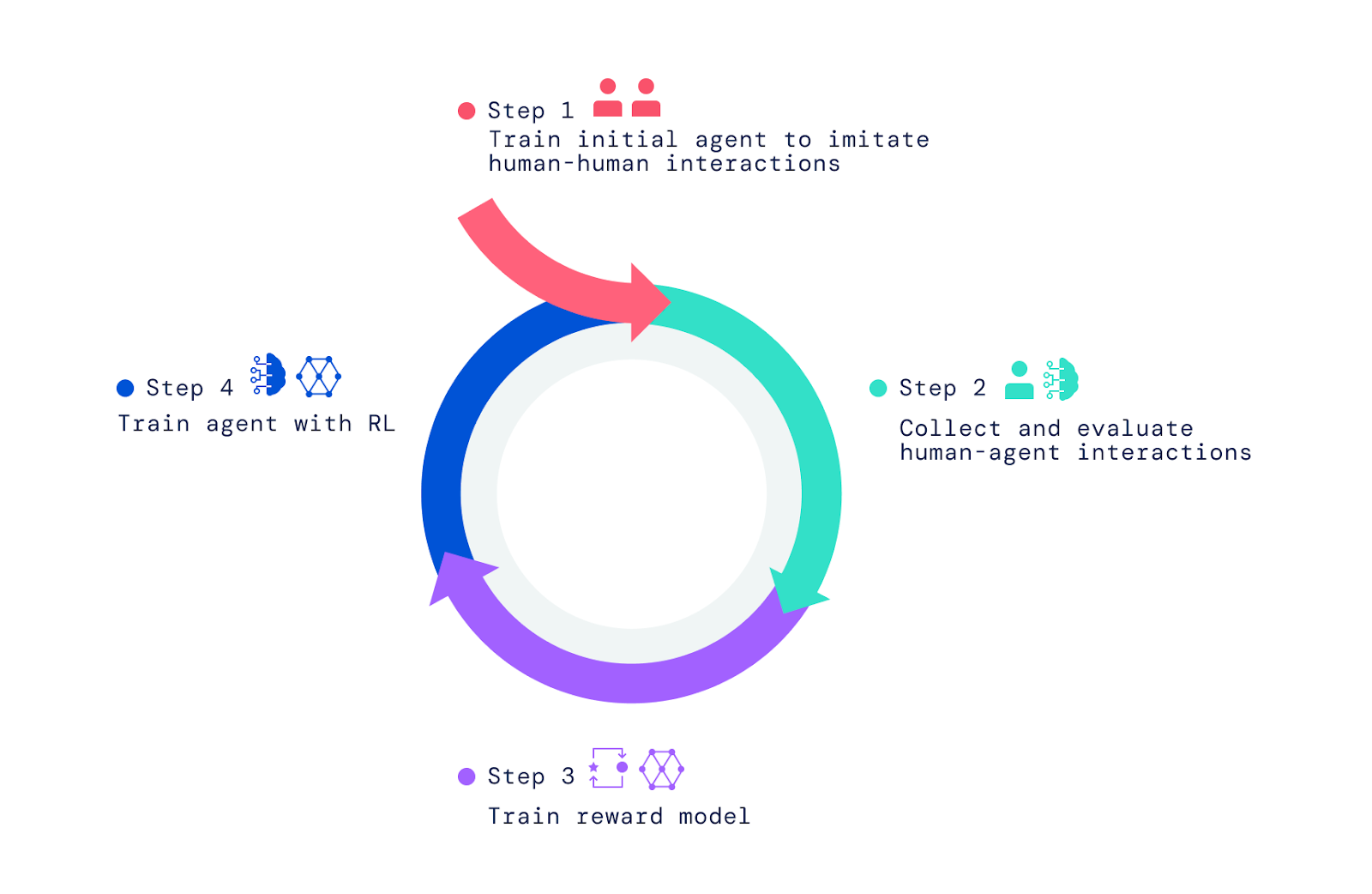
Pour créer nos agents IA, nous avons appliqué trois étapes. Nous avons commencé par former des agents à imiter les éléments de base d’interactions humaines simples dans lesquelles une personne demande à une autre personne de faire quelque chose ou de répondre à une question. Nous appelons cette étape l’établissement d’un comportement préconçu qui permet aux agents d’avoir des interactions significatives avec l’humain à une fréquence élevée. Sans cette étape d’imitation, les clients se déplacent au hasard et disent des bêtises. Il est presque impossible d’interagir avec eux de manière raisonnable et de leur donner des commentaires encore plus difficiles. Cette étape a été couverte dans deux de nos précédents articles, Imitation of Interactive Intelligence et Creation of Interactive Multimedia Agents Using Imitation and Self-Learning, qui ont exploré la construction d’agents basés sur l’imitation.
Aller au-delà de l’apprentissage par imitation
Alors que l’apprentissage par simulation conduit à des interactions intéressantes, il traite chaque moment de l’interaction comme tout aussi important. Pour apprendre un comportement efficace et orienté vers un objectif, l’agent doit suivre la cible et maîtriser certains mouvements et décisions à des moments cruciaux. Par exemple, les agents mimiques ne prennent pas de manière fiable des raccourcis ou n’exécutent pas des tâches plus habilement qu’un joueur humain normal.
Ici, nous montrons un opérateur basé sur l’apprentissage simulé et un opérateur basé sur RL qui suivent les mêmes instructions humaines :
Pour donner à nos agents un sens du but et aller au-delà de ce qui est possible grâce à l’imitation, nous nous sommes appuyés sur RL, qui utilise des essais et des erreurs ainsi que des analyses comparatives pour une amélioration itérative. Lorsque nos agents tentaient différentes actions, celles qui amélioraient les performances étaient renforcées, tandis que celles qui diminuaient les performances étaient punies.
Dans des jeux comme Atari, Dota, Go et StarCraft, le score fournit une mesure de performance qui doit être améliorée. Au lieu d’utiliser le score, nous avons demandé aux humains d’évaluer les situations et de fournir des commentaires, ce qui a aidé nos agents apprendre Modèle de récompense.
Formation au modèle de récompense et amélioration des agents
Pour entraîner le paradigme de la récompense, nous avons demandé aux humains de juger s’ils avaient remarqué des événements qui indiquaient des progrès clairs vers l’objectif actuel, des erreurs ou des erreurs évidentes. Nous avons ensuite établi une correspondance entre ces événements positifs et négatifs et les préférences positives et négatives. Parce qu’ils se produisent dans le temps, nous appelons ces jugements “entre les temps”. Nous avons formé un réseau de neurones pour prédire ces préférences humaines et avons ainsi obtenu un modèle de récompense (ou utilité/score) qui reflétait les réponses humaines.
Une fois le modèle de récompense formé à l’aide des préférences humaines, nous l’avons utilisé pour améliorer les agents. Nous avons placé nos agents dans le simulateur et leur avons demandé de répondre aux questions et de suivre les instructions. Au fur et à mesure qu’ils agissaient et parlaient dans l’environnement, le modèle de récompense entraîné enregistrait leur comportement et nous avons utilisé l’algorithme RL pour améliorer les performances de l’agent.
Alors, d’où viennent les instructions de mission et les questions ? Nous avons exploré deux approches pour cela. Tout d’abord, nous avons recyclé les tâches et les questions posées dans notre ensemble de données humaines. Deuxièmement, nous avons formé les agents pour imiter la façon dont les humains attribuent des tâches et posent des questions, comme le montre cette vidéo, où deux agents, l’un formé pour imiter les humains lors de la définition des tâches et de poser des questions (bleu) et l’autre formé pour suivre les instructions et répondre aux questions (jaune), interagir les uns avec les autres :
Évaluation et itération pour améliorer encore les agents
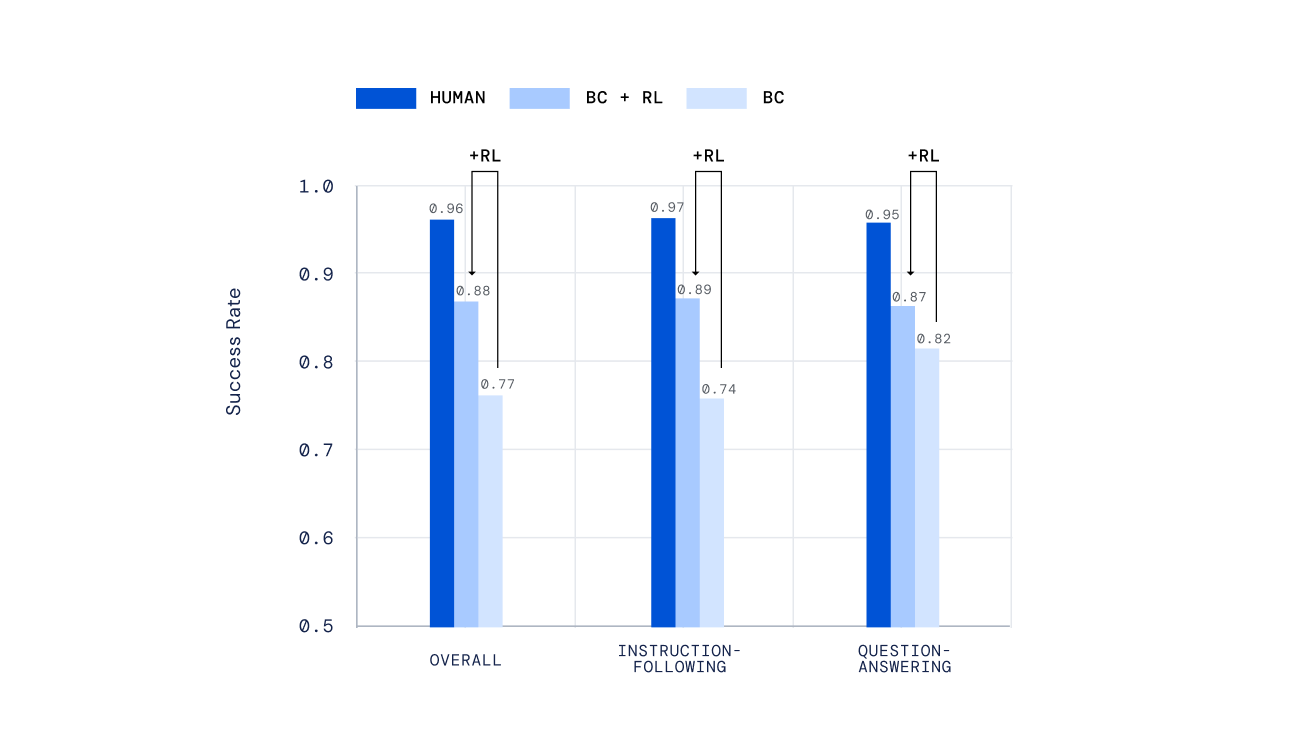
Nous avons utilisé une variété de mécanismes indépendants pour évaluer nos agents, allant des tests manuscrits à un nouveau mécanisme de notation humaine hors ligne pour les tâches ouvertes générées par le sujet, développé dans notre travail précédent, Evaluation of Multimodal Interactive Agents. Plus important encore, nous avons demandé aux gens d’interagir avec nos agents en temps réel et de juger de leurs performances. Nos agents formés par RL ont obtenu des résultats significativement meilleurs que ceux formés par apprentissage simulé seul.
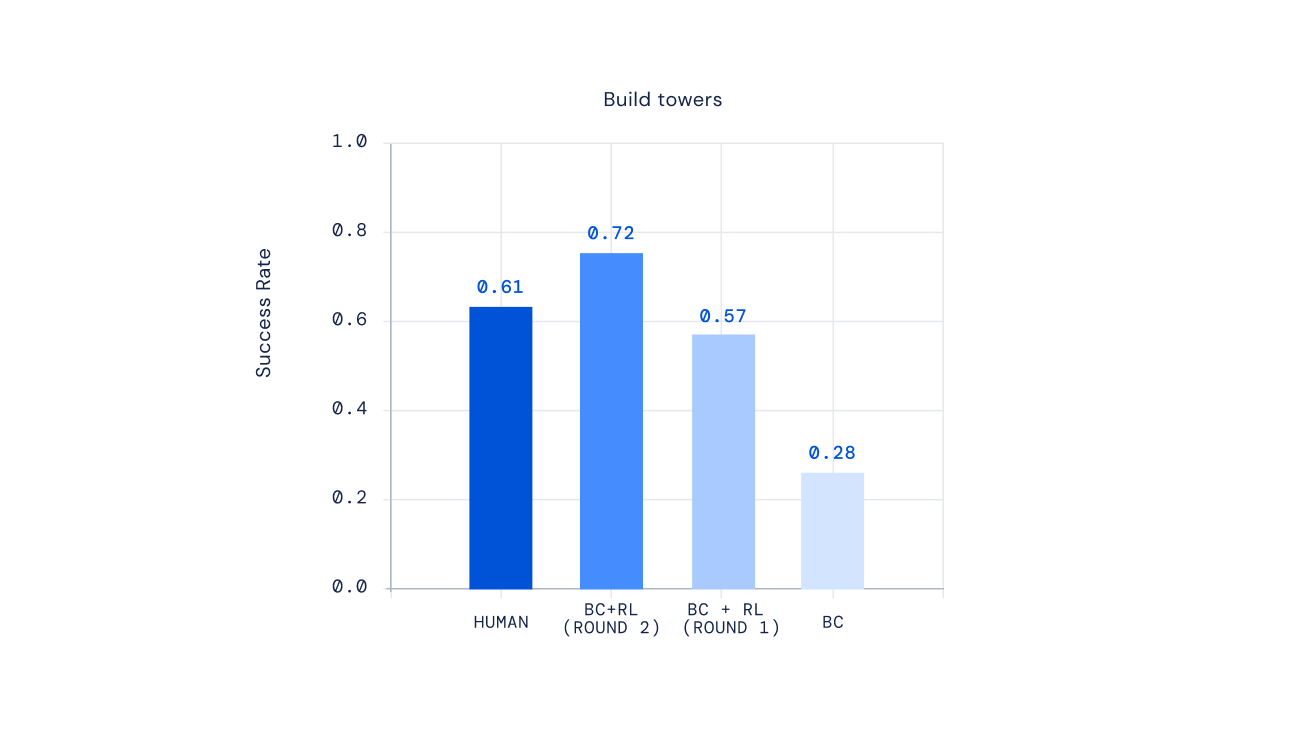
Enfin, des expériences récentes montrent que nous pouvons itérer le processus RL pour améliorer de manière itérative le comportement des agents. Une fois l’agent formé via RL, nous avons demandé aux sujets d’interagir avec ce nouvel agent, de commenter son comportement, de mettre à jour notre modèle de récompense, puis d’effectuer une autre itération du RL. Le résultat de cette approche a été des agents de plus en plus efficaces. Pour certains types d’instructions complexes, nous pourrions même créer des proxys qui surpassaient en moyenne les joueurs humains.
L’avenir de la formation de l’intelligence artificielle pour déterminer les préférences humaines
L’idée d’entraîner l’IA à utiliser les préférences humaines comme récompense existe depuis longtemps. Dans l’apprentissage par renforcement profond des préférences humaines, les chercheurs ont mis au point des méthodes de pointe pour faire correspondre les facteurs basés sur les réseaux neuronaux aux préférences humaines. Des travaux récents sur le développement d’agents de dialogue basés sur les rôles ont exploré des idées similaires pour la formation d’assistants utilisant RL à partir de la rétroaction humaine. Nos recherches ont adapté et étendu ces connaissances pour créer des systèmes d’IA flexibles capables de maîtriser un large éventail d’interactions multimodales et incarnées en temps réel avec les gens.
Nous espérons que notre cadre créera un jour une IA de jeu capable de répondre naturellement à nos significations exprimées, plutôt que de s’appuyer sur des schémas comportementaux écrits à la main. Notre cadre peut également être utile pour créer des assistants numériques et robotiques avec lesquels les gens peuvent interagir au quotidien. Nous sommes impatients d’explorer la possibilité d’appliquer des éléments de ce cadre pour créer une IA vraiment sûre et utile.
Envie d’en savoir plus ? Découvrez nos derniers articles. Les remarques et commentaires sont les bienvenus.