
Alors que les modèles de diffusion sont désormais considérés comme la génération la plus récente de modèles texte-image, ils sont apparus comme une “technologie perturbatrice” qui met en valeur des compétences inouïes dans la création d’images de haute qualité et diverses à partir d’invites textuelles. La capacité de donner aux utilisateurs un contrôle intuitif sur le matériel créé reste un défi pour les modèles texte-image, bien que cette avancée recèle un grand potentiel pour transformer la façon dont le contenu numérique est créé.
À l’heure actuelle, il existe deux façons d’organiser les modèles de propagation : (1) former un modèle à partir de zéro ou (2) affiner un modèle de propagation existant pour la fonction actuelle. Même dans un scénario de réglage fin, cette stratégie nécessite souvent des calculs importants et une longue période de développement en raison du volume sans cesse croissant de modèles et de données d’entraînement. (2) Réutilisez un modèle déjà formé et ajoutez des fonctionnalités de génération contrôlée. Certaines technologies se concentraient auparavant sur des tâches spécifiques et créaient une méthodologie spécialisée. Cette étude vise à établir MultiDiffusion, un nouveau cadre unifié qui améliore considérablement l’adaptabilité d’un modèle de diffusion pré-formé (de référence) pour la production d’images contrôlées.

L’objectif principal de MultiDiffusion est de concevoir un nouveau processus de génération qui comprend plusieurs processus de génération de diffusion de référence associés à un ensemble commun de propriétés ou de contraintes. Les différentes régions de l’image résultante sont soumises au modèle de diffusion de référence, qui prédit plus précisément le pas de réduction du bruit d’échantillonnage pour chacune. MultiDiffusion effectue ensuite une étape d’échantillonnage global, en utilisant une meilleure solution des moindres carrés, pour réconcilier toutes ces phases discrètes. Considérez, par exemple, le défi de créer une image dans n’importe quel rapport d’aspect à l’aide d’un modèle de déploiement de référence formé sur des images carrées (voir la figure 2 ci-dessous).
🚨 Lisez notre dernière newsletter AI🚨
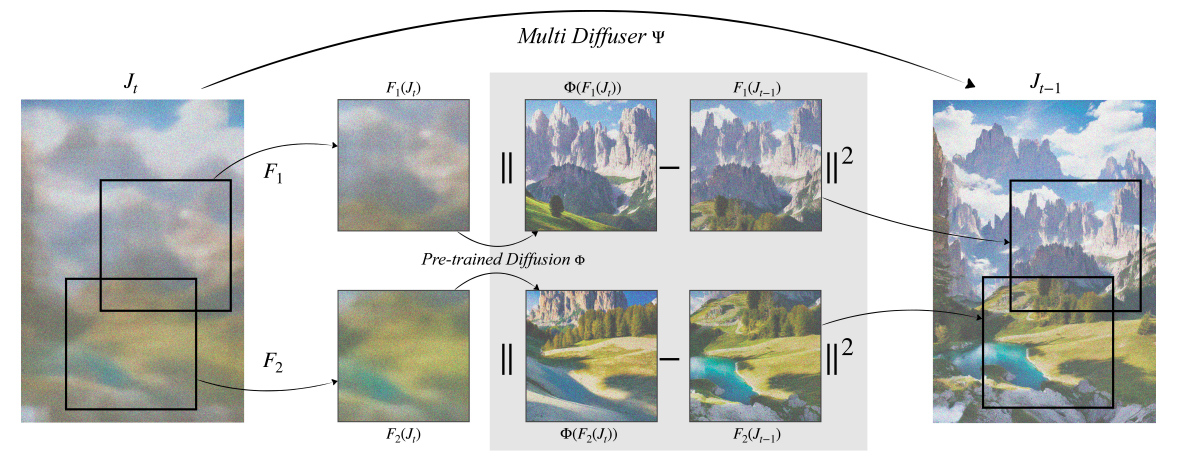
MultiDiffusion intègre les tendances de débruitage de toutes les cultures carrées fournies par le modèle de référence à chaque étape du processus de débruitage. Il essaie de les suivre tous au plus près, étant gêné par les cultures voisines qui partagent des pixels communs. Bien que chaque recadrage puisse tirer dans une direction évidente de réduction du bruit, il convient de noter que leur cadre entraîne une seule étape de réduction du bruit, ce qui donne des images fluides et de haute qualité. Il faut amener chaque culture à représenter un véritable échantillon du modèle de référence.
À l’aide de MultiDiffusion, ils peuvent appliquer un modèle de référence texte-image pré-formé à une variété de tâches, telles que la création d’images à une résolution ou un rapport d’aspect spécifique ou la création d’images à partir d’invites de texte illisibles basées sur une région, comme indiqué dans le chiffre. 1. Remarquablement, sa structure permet la solution simultanée des deux tâches grâce à l’utilisation d’un processus de développement commun. Ils ont découvert que leur méthodologie pouvait atteindre une génération contrôlée de pointe même par rapport à des approches spécialement formées pour ces fonctions en les comparant à des lignes de base pertinentes. De plus, leur approche fonctionne efficacement sans ajouter de surcharge de calcul. La base de code complète sera bientôt publiée sur leur page Github. On peut également voir plus de démos sur leur page de projet.
scanner le papierEt githubEt Page du projet. Tout le mérite de cette recherche revient aux chercheurs de ce projet. N’oubliez pas non plus de vous inscrire 14k + ML Sous RedditEt canal de discordeEt Courrieloù nous partageons les dernières nouvelles sur la recherche en IA, des projets d’IA sympas, et plus encore.
Anish Teeku est consultant stagiaire chez MarktechPost. Il poursuit actuellement ses études de premier cycle en science des données et en intelligence artificielle à l’Institut indien de technologie (IIT) de Bhilai. Il passe la plupart de son temps à travailler sur des projets visant à exploiter la puissance de l’apprentissage automatique. Ses intérêts de recherche portent sur le traitement d’images et il est passionné par la création de solutions autour de celui-ci. Aime communiquer avec les gens et collaborer sur des projets intéressants.