
La nouvelle définition formelle de l’agence donne des principes clairs pour la modélisation causale des agents d’IA et les incitations qu’ils rencontrent
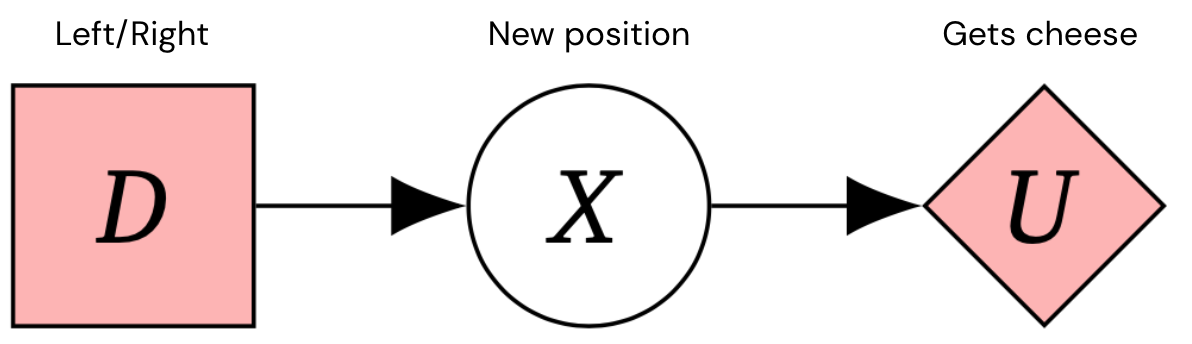
Nous voulons construire des systèmes d’intelligence générale artificielle (IAG) sûrs et cohérents qui poursuivent les objectifs visés par leurs concepteurs. Les diagrammes d’influence causale (CID) sont un moyen de modéliser des situations de prise de décision qui nous permettent de réfléchir aux incitations d’un agent. Par exemple, voici le CID pour un processus de décision de Markov en une étape – un cadre typique pour les problèmes de prise de décision.

En liant les paramètres de formation aux stimuli qui façonnent le comportement des agents, les CID aident à éclairer les risques potentiels avant la formation des agents et peuvent inspirer de meilleures conceptions d’agents. Mais comment savoir si un CID est un modèle précis pour un cadre de formation ?
Notre nouvel article, Agent Discovery, présente de nouvelles façons de résoudre ces problèmes, notamment :
- Première définition causale formelle des facteurs : Les agents sont des systèmes qui adapteront leur politique si leurs actions affectent le monde d’une manière différente
- Un algorithme pour découvrir des facteurs à partir de données expérimentales
- Traduire entre les modèles de causalité et les CID
- Résoudre les confusions précédentes dues à une modélisation causale incorrecte des facteurs
Pris ensemble, ces résultats fournissent une couche supplémentaire d’assurance qu’aucune erreur de modélisation ne s’est produite, ce qui signifie que les CID peuvent être utilisés pour analyser les incitations des agents et les caractéristiques de sécurité avec une plus grande confiance.
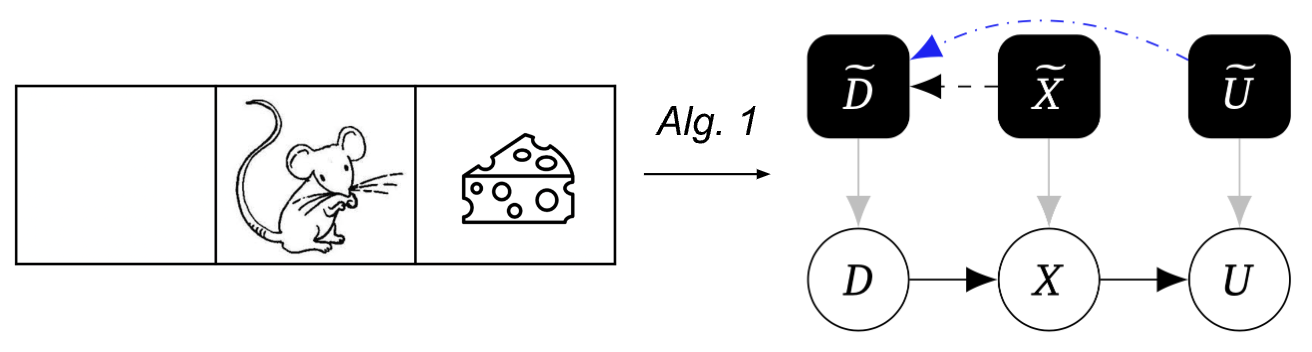
Exemple : Modélisation d’une souris en tant que travailleur
Pour aider à illustrer notre méthode, considérons l’exemple suivant composé d’un monde avec trois carrés, où la souris commence sur le carré du milieu et choisit de se déplacer vers la gauche ou la droite, d’atteindre sa position suivante, puis d’obtenir du fromage. Le sol est glacé, donc la souris peut glisser. Parfois le fromage est à droite, parfois à gauche.

Cela peut être représenté par le CID suivant :
L’intuition qu’une souris choisira un comportement différent pour différents paramètres d’environnement (glace, distribution de fromage) peut être capturée par un graphe causal mécanique, Qui pour chaque variable (au niveau de l’objet), comprend également une variable de mécanisme qui contrôle la façon dont la variable dépend de son parent. De manière cruciale, nous permettons des liens entre les variables de mécanisme.
Ce graphique contient des nœuds automatiques supplémentaires en noir, représentant la politique de la souris et la distribution du fromage et du fromage.
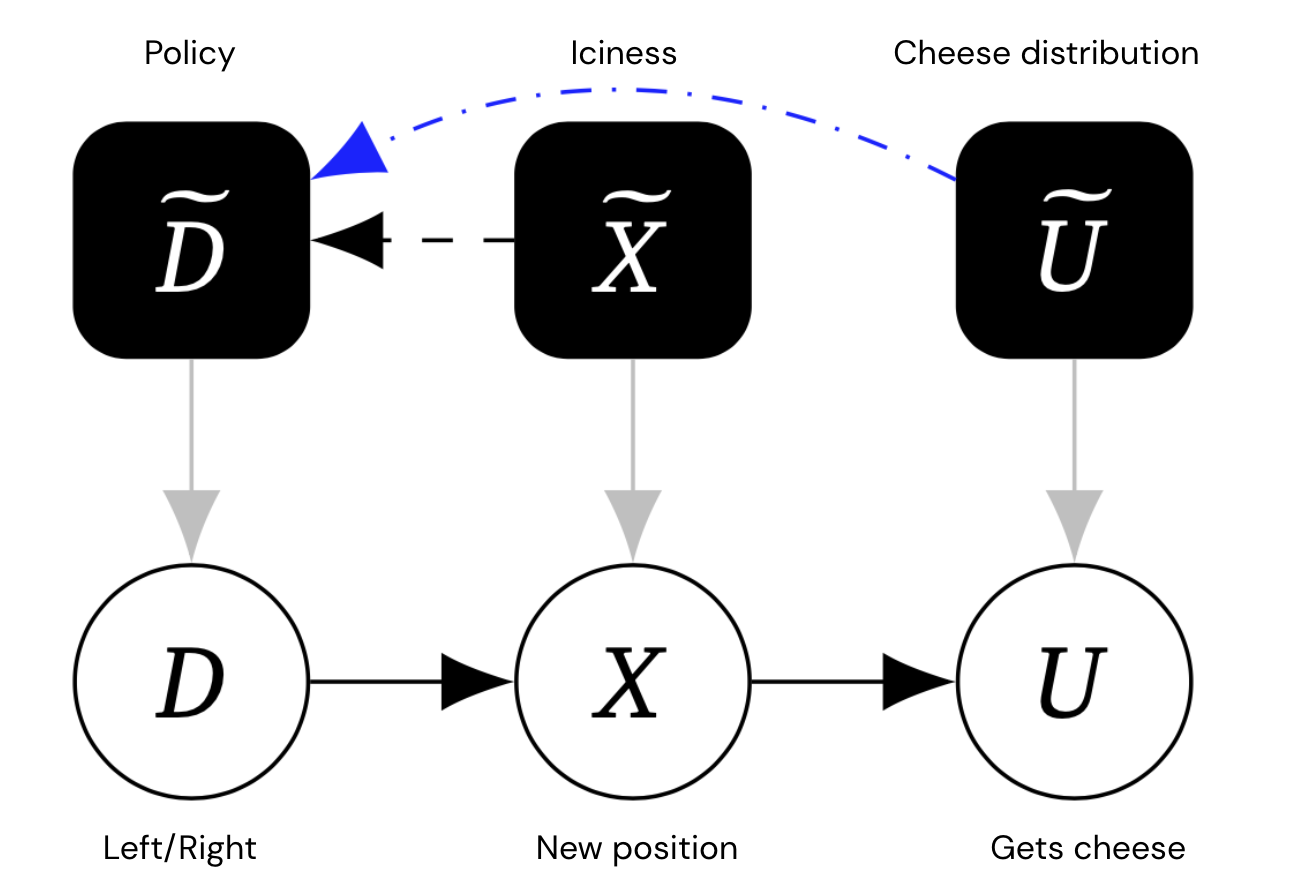
Les bords entre les mécanismes représentent un effet causal direct. Bords particulièrement bleus salon Arêtes – En gros, les arêtes du mécanisme A ~→B~ qui existeront toujours, même si la variable de niveau objet A a été modifiée de sorte qu’elle n’ait pas d’arêtes sortantes.
Dans l’exemple ci-dessus, puisque U n’a pas d’enfants, son arête de mécanisme doit être terminale. Mais le bord du mécanisme X → → D ~ n’est pas définitif, car si on coupe X de son enfant U, la souris ne s’adaptera plus à sa décision (car sa position n’affectera pas si elle obtient du fromage).
La découverte des facteurs de causalité
La découverte causale dérive un graphe causal d’expériences impliquant des interventions. En particulier, on peut détecter une flèche de la variable A à la variable B en intervenant expérimentalement sur A et en vérifiant si B répond, même si toutes les autres variables sont maintenues constantes.
Notre premier algorithme utilise cette technique pour la détection automatisée de graphe causal :
Le deuxième algorithme transforme ce graphe causal automatisé en un graphe de jeu :
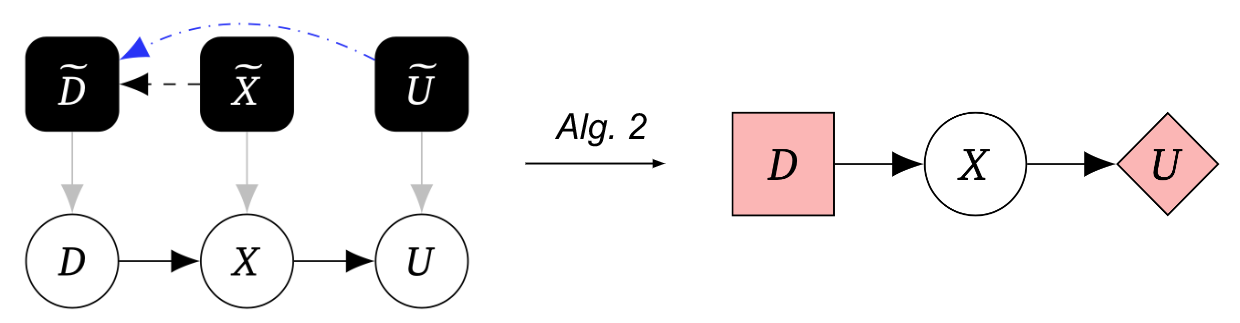
Pris ensemble, l’algorithme 1 suivi de l’algorithme 2 nous permet de détecter des facteurs à partir d’expériences causales et de les représenter à l’aide de CID.
Le troisième algorithme convertit le graphe du jeu en un graphe causal mécanique, nous permettant de traduire entre les représentations du graphe causal du jeu et de la machine sous quelques hypothèses supplémentaires :
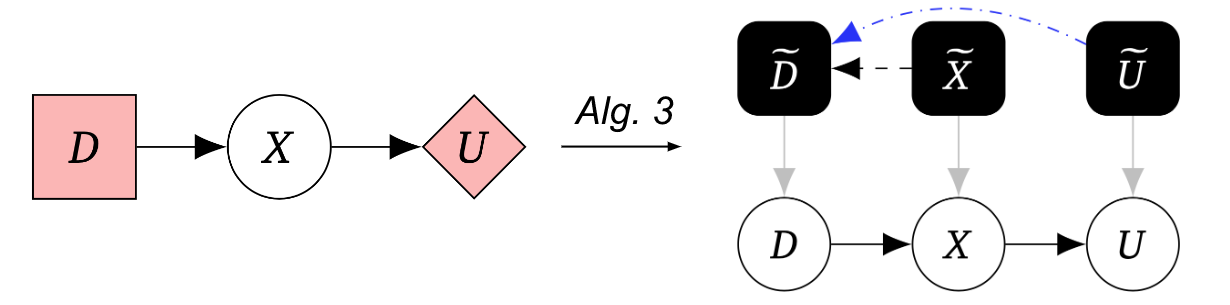
De meilleurs outils de sécurité pour la modélisation des agents IA
Nous avons proposé la première définition causale formelle des facteurs. Notre idée de base est basée sur la découverte causale, que les agents sont des systèmes qui adaptent leur comportement en réponse aux changements dans la façon dont leurs actions affectent le monde. En fait, nos algorithmes 1 et 2 décrivent un processus expérimental rigoureux qui peut aider à évaluer si un système contient un agent.
L’intérêt pour la modélisation causale des systèmes d’IA croît rapidement, et nos recherches fondent cette modélisation sur des expériences de découverte causale. Notre article démontre le potentiel de notre approche en améliorant l’analyse de l’intégrité de nombreux systèmes d’IA, et démontre que la causalité est un cadre utile pour détecter si un agent est impliqué dans un système, une préoccupation clé pour l’évaluation des risques de l’IA.
Envie d’en savoir plus ? Consultez notre papier. Les commentaires et remarques sont les bienvenus