
Ces dernières années, la production de contenus de modèles génératifs a fait des progrès significatifs, permettant une synthèse d’images et de vidéos de haute qualité, contrôlée par l’utilisateur. Les utilisateurs peuvent créer et modifier de manière interactive une image haute résolution à l’aide d’une carte d’étiquettes d’entrée 2D et de techniques de traduction d’image à image. Cependant, les techniques actuelles de traduction d’image à image ne fonctionnent qu’en 2D et ne prennent pas explicitement en compte la structure 3D sous-jacente du contenu. Comme l’illustre la figure 1, leur objectif est de rendre la synthèse d’images conditionnelle sensible à la 3D, permettant la création de textures 3D, la manipulation de vues et la modification d’attributs (par exemple, la modification de la forme des voitures en 3D). Il peut être difficile de créer un matériau 3D basé sur une intervention humaine. Obtenir d’énormes ensembles de données avec des entrées utilisateur associées et des sorties 3D prévues coûte cher pour former le modèle.
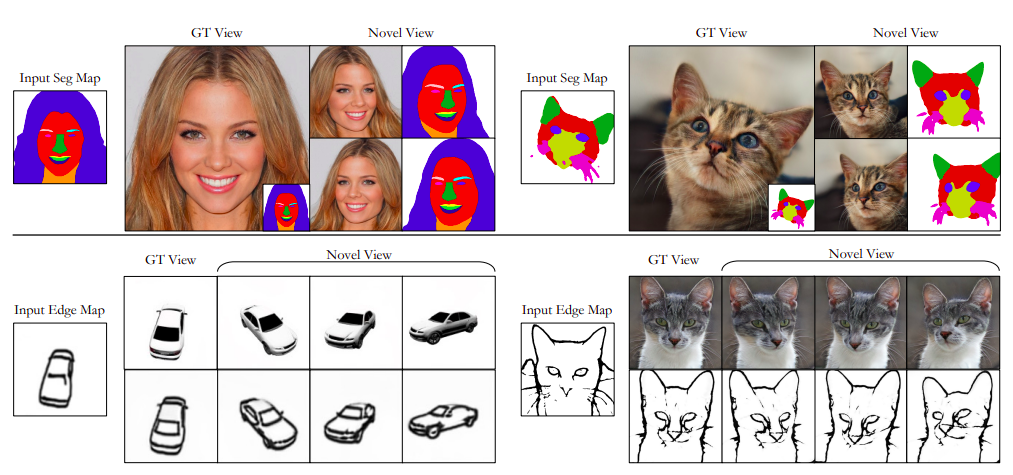
Alors qu’un utilisateur peut vouloir décrire les détails d’objets 3D à l’aide d’interfaces 2D sous différents angles, la production de contenu 3D nécessite souvent l’entrée d’un utilisateur multi-visualiseur. Pendant ce temps, ces entrées ne peuvent pas être compatibles 3D, donnant des signaux contradictoires pour la production de contenu 3D. Pour surmonter ces problèmes, ils ont appliqué des représentations de paysages neuronaux 3D à des modèles génératifs conditionnels. Ils contiennent également des informations sémantiques 3D pour faciliter l’édition croisée, qui peuvent ensuite être présentées sous forme de cartes d’étiquettes 2D sous différents angles. Ils n’ont besoin que d’une supervision bidimensionnelle sous forme de reconstruction d’image et de pertes antagonistes pour apprendre la représentation tridimensionnelle susmentionnée.
Cependant, le surligneur conditionnel aligné sur les pixels améliore l’apparence et les étiquettes pour qu’elles paraissent réalistes lors de l’alignement des pixels lorsqu’elles sont affichées dans de nouvelles vues. Dans le même temps, la perte de reconstruction assure l’alignement entre les entrées 2D de l’utilisateur et les matériaux 3D correspondants. Ils proposent également une perte de symétrie croisée pour exiger que les symboles latents soient cohérents entre différents points de vue. Ils se concentrent sur les ensembles de données CelebAMAsk-HQ, AFHQ-cat et shapenetcar pour la synthèse d’images sémantiques 3D. Leur approche utilise efficacement différentes entrées utilisateur 2D, telles que des cartes de segmentation et des cartes de bord. Leur approche va au-delà de plusieurs lignes de base 2D et 3D, y compris les versions de SEAN, SofGAN et Pix2NeRF. En outre, ils minimisent les effets des différentes décisions de conception et montrent comment leur méthodologie peut être utilisée dans des applications telles que l’édition de vues croisées et le contrôle explicite de l’utilisateur sur la sémantique et le style.
🚨 Lisez notre dernière newsletter AI🚨
Pour voir plus de résultats et de code, visitez leur site Web. Leur approche actuelle présente deux inconvénients importants. Premièrement, il se concentre principalement sur la modélisation de la forme et de la géométrie d’un type d’élément. Cependant, déterminer la situation juridique des scènes publiques est une tâche difficile. Une prochaine étape intéressante consiste à étendre l’approche à des ensembles de données de scène plus complexes avec de nombreux objets. Deuxièmement, leur formation de modèle nécessite des positions de caméra associées à chaque image de formation, tandis que leur approche ne nécessite pas de positions pendant le temps d’inférence. La gamme d’applications sera encore élargie en éliminant le besoin d’informations de position.
scanner le papierEt projetEt github. Tout le mérite de cette recherche revient aux chercheurs de ce projet. N’oubliez pas non plus de vous inscrire 14k + ML Sous RedditEt canal de discordeEt Courrieloù nous partageons les dernières nouvelles sur la recherche en IA, des projets d’IA sympas, et plus encore.
Anish Teeku est consultant stagiaire chez MarktechPost. Il poursuit actuellement ses études de premier cycle en science des données et en intelligence artificielle à l’Institut indien de technologie (IIT) de Bhilai. Il passe la plupart de son temps à travailler sur des projets visant à exploiter la puissance de l’apprentissage automatique. Ses intérêts de recherche portent sur le traitement d’images et il est passionné par la création de solutions autour de celui-ci. Aime communiquer avec les gens et collaborer sur des projets intéressants.