
En 2016, nous avons introduit Alpha Go, le premier programme d’IA à vaincre les humains dans l’ancien jeu de Go. Deux ans plus tard, derrière elle – Alpha zéro Apprenez à partir de zéro pour maîtriser Go, les échecs et le shogi. maintenant, Dans un article de la revue NatureMuZero est une avancée significative dans la recherche d’algorithmes à usage général. MuZero Masters Go, échecs, shogi et Atari sans avoir à leur dire les règles, grâce à sa capacité à planifier des stratégies gagnantes dans des environnements inconnus.
Pendant de nombreuses années, les chercheurs ont cherché des moyens d’apprendre un modèle qui explique leur environnement, puis d’utiliser ce modèle pour planifier le meilleur plan d’action. Jusqu’à présent, la plupart des approches ont eu du mal à tracer efficacement dans des domaines, tels que celui d’Atari, où les règles ou la dynamique sont généralement inconnues et complexes.
MuZero, présenté pour la première fois dans un article préliminaire en 2019, résout ce problème en apprenant un modèle qui se concentre uniquement sur les aspects les plus importants de l’environnement pour la planification. En combinant ce modèle avec la puissante recherche arborescente d’AlphaZero, MuZero établit un nouveau score de pointe sur la norme Atari, tout en égalant les performances d’AlphaZero sur les défis de mise en page classiques comme le Go, les échecs et le shoji. Ce faisant, MuZero démontre un énorme bond en avant dans les capacités des algorithmes d’apprentissage par renforcement.

Modèles circulaires à inconnus
La capacité de planifier est une partie importante de l’intelligence humaine, nous permettant de résoudre des problèmes et de prendre des décisions concernant l’avenir. Par exemple, si nous voyons des nuages sombres se former, nous pouvons nous attendre à ce qu’il pleuve et décider de prendre un parapluie avec nous avant de partir. Les humains apprennent rapidement cette capacité et peuvent généraliser à de nouveaux scénarios, ce qui est une caractéristique que nous aimerions également que nos algorithmes aient.
Les chercheurs ont tenté de relever ce défi majeur de l’IA en utilisant deux approches principales : l’introspection ou la planification basée sur des modèles.
Les systèmes qui utilisent la recherche anticipée, comme AlphaZero, ont connu un succès remarquable dans les jeux classiques comme les dames, les échecs et le poker, mais ils dépendent de la connaissance de la dynamique de leur environnement, comme les règles du jeu ou un simulateur précis. Cela rend difficile son application à des problèmes désordonnés du monde réel, qui sont généralement complexes et difficiles à distiller en règles simples.
Les systèmes basés sur des modèles visent à résoudre ce problème en apprenant un modèle précis de la dynamique de l’environnement, puis en l’utilisant pour la planification. Cependant, la complexité de la modélisation de chaque aspect de l’environnement signifie que ces algorithmes sont incapables de rivaliser dans des domaines visuellement riches, comme celui d’Atari. Jusqu’à présent, les meilleurs résultats sur Atari proviennent de systèmes sans modèle, tels que DQN, R2D2 et Agent57. Comme leur nom l’indique, les algorithmes sans modèle n’utilisent pas de modèle appris et estiment plutôt quelle est la meilleure action à entreprendre ensuite.
MuZero utilise une approche différente pour surmonter les limites des méthodes précédentes. Plutôt que d’essayer de modéliser l’ensemble de l’environnement, MuZero ne modélise que les aspects importants du processus de prise de décision d’un agent. Après tout, savoir qu’un parapluie vous gardera au sec est plus utile que de connaître le motif des gouttes de pluie dans l’air.
Plus précisément, MuZero modélise trois éléments de l’environnement qui sont essentiels à la planification :
- le valeur: Quelle est la situation actuelle ?
- le Politique: Quelle est la meilleure marche à suivre ?
- le prix: Quelle est la qualité des travaux récents ?
Tout est appris à l’aide d’un réseau neuronal profond et c’est tout ce dont MuZero a besoin pour comprendre ce qui se passe lorsqu’il entreprend une certaine action et planifier en conséquence.



Cette approche présente un autre avantage majeur : MuZero peut utiliser son modèle appris de manière itérative pour améliorer sa mise en page, plutôt que de collecter de nouvelles données à partir de l’environnement. Par exemple, lors de tests sur la suite Atari, cette variante – connue sous le nom de MuZero Reanalyze – a utilisé le modèle appris 90% du temps pour remapper ce qui devait être fait dans les épisodes précédents.
Performances MuZero
Nous avons choisi quatre domaines différents pour tester les capacités de MuZeros. Le go, les échecs et le shogi ont été utilisés pour évaluer ses performances sur des problèmes de mise en page difficiles, tandis que nous avons utilisé la suite Atari comme référence pour des problèmes visuellement plus complexes. Dans tous les cas, MuZero a établi un nouvel état de l’art pour les algorithmes d’apprentissage par renforcement, surpassant tous les algorithmes précédents de la suite Atari et correspondant aux performances exceptionnelles d’AlphaZero sur Go, aux échecs et au shogi.

Nous avons également testé plus en détail la qualité des graphiques de MuZero avec son modèle appris. Nous avons commencé avec le défi classique de la planification de précision en Go, où un seul mouvement peut faire la différence entre gagner et perdre. Pour confirmer l’intuition que planifier plus devrait conduire à de meilleurs résultats, nous avons mesuré la puissance d’une version entièrement entraînée de MuZero lorsqu’on lui a donné plus de temps pour planifier chaque mouvement (voir le graphique de gauche ci-dessous). Les résultats montrent que la force du jeu augmente de plus de 1000 Elo (une mesure de la compétence relative d’un joueur) lorsque nous augmentons le temps par coup d’un dixième de seconde à 50 secondes. Ceci est similaire à la différence entre un joueur amateur fort et un joueur professionnel fort.
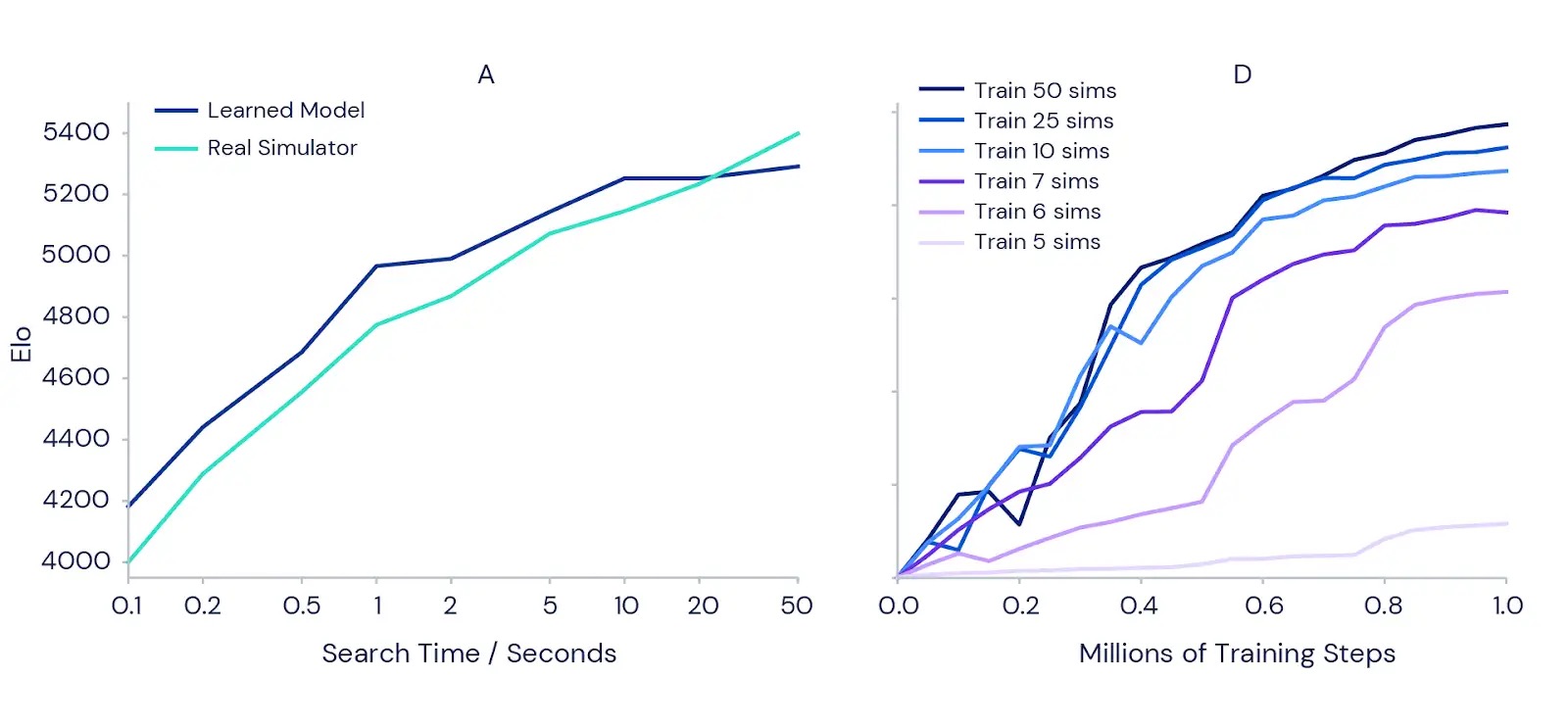
Pour tester si la planification apporte également des avantages pendant la formation, nous avons effectué une série d’expériences sur le jeu Atari Ms. Pac-Man (diagramme de droite ci-dessus) en utilisant des instances séparées de MuZero. Chacun a été autorisé à envisager un nombre différent de simulations de planification par mouvement, allant de cinq à 50. Les résultats ont confirmé que l’augmentation du nombre de planifications par mouvement permet à MuZero d’apprendre plus rapidement et d’obtenir de meilleures performances finales.
Fait intéressant, lorsque MuZero n’était autorisé à envisager que six ou sept simulations de chaque mouvement – un nombre trop petit pour couvrir toutes les actions disponibles dans Mme Pac-Man – cela s’est plutôt bien passé. Cela indique que MuZero est capable de généraliser entre actions et situations, et n’a pas besoin de rechercher de manière exhaustive toutes les possibilités pour apprendre efficacement.
nouveaux horizons
La capacité de MuZero à apprendre un modèle de son environnement et à l’utiliser pour une planification réussie montre une avancée significative dans l’apprentissage par renforcement et la recherche d’algorithmes à usage général. Son prédécesseur, AlphaZero, a déjà été appliqué à une gamme de problèmes complexes en chimie, en physique quantique et au-delà. Les idées derrière les puissants algorithmes d’apprentissage et de planification de MuZero pourraient ouvrir la voie à de nouveaux défis dans la robotique, les systèmes industriels et d’autres environnements chaotiques du monde réel où les “règles du jeu” sont inconnues.
Liens connexes: