

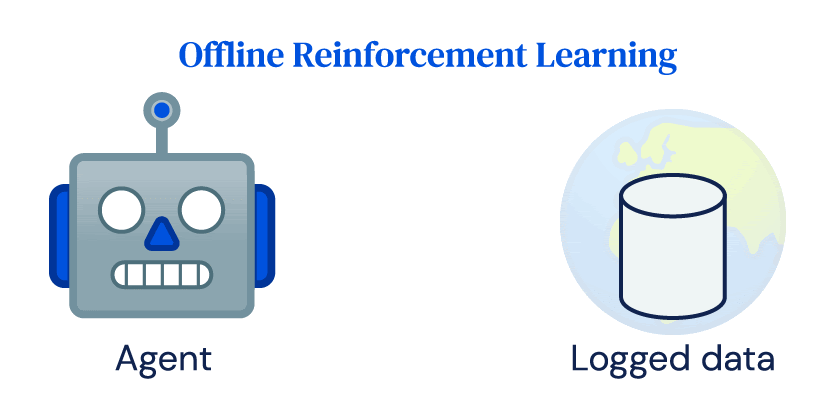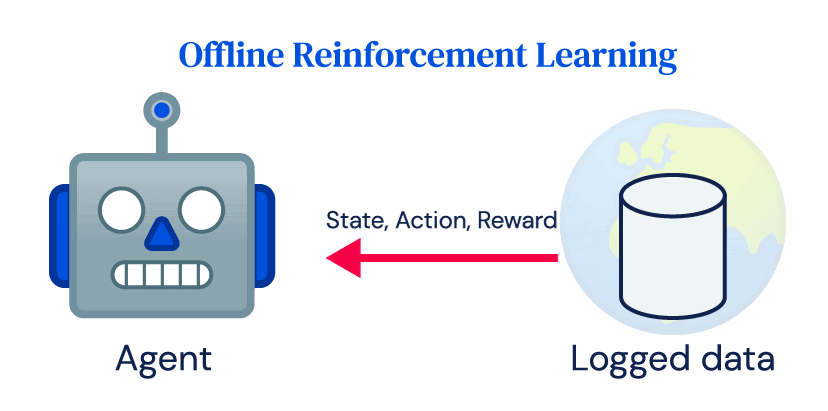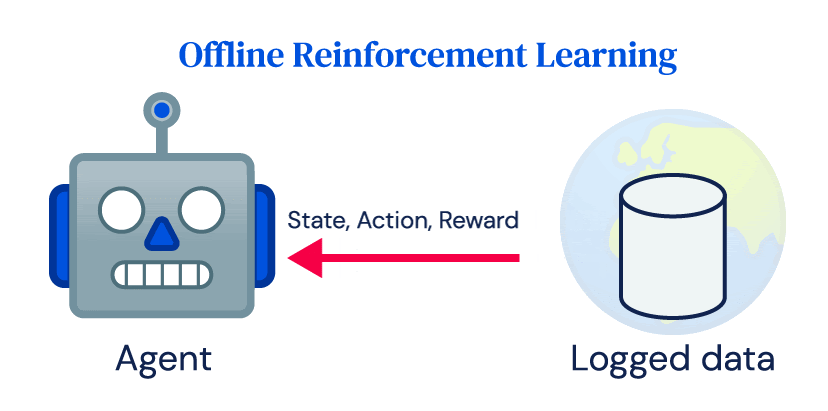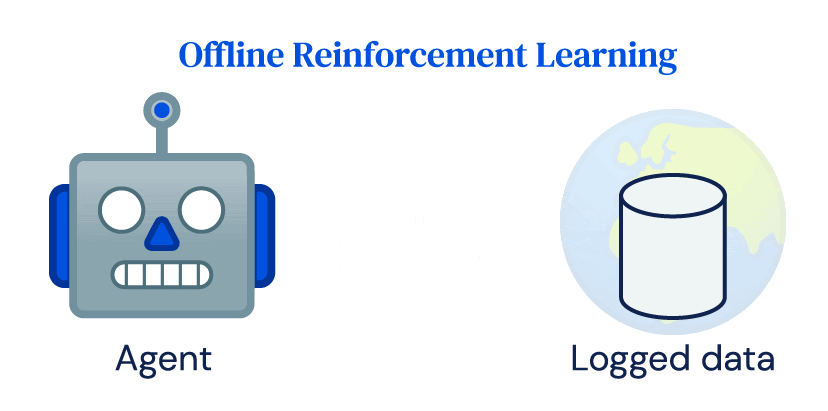
De nombreux succès de RL dépendent fortement des interactions en ligne fréquentes de l’agent avec l’environnement, que nous appelons RL en ligne. Malgré son succès dans la simulation, l’adoption de RL pour les applications du monde réel a été limitée. Les centrales électriques, les robots, les systèmes de santé ou les voitures autonomes coûtent cher et un contrôle inapproprié peut avoir de graves conséquences. Il ne se conforme pas facilement à l’idée de base de l’exploration dans RL et aux exigences de données des algorithmes RL en ligne. Cependant, la plupart des systèmes du monde réel produisent de grandes quantités de données dans le cadre de leur fonctionnement normal, et l’objectif de la RL hors ligne est d’apprendre la politique directement à partir de ces données enregistrées sans interagir avec l’environnement.
Les méthodes RL hors ligne (par exemple Agarwal et al., 2020 ; Fujimoto et al., 2018) ont montré des résultats prometteurs dans des domaines bien connus de l’analyse comparative. Cependant, des protocoles d’évaluation non normalisés, des ensembles de données différents et de nombreuses bases de référence rendent les comparaisons informatiques difficiles. Cependant, certaines propriétés importantes des domaines d’application potentiels du monde réel, telles que l’observabilité partielle, les flux sensoriels de grande dimension (c’est-à-dire les images), les divers espaces de travail, les problèmes d’exploration, l’instabilité et le caractère aléatoire, sont sous-représentées dans la littérature actuelle de RL sans contact. l’Internet. .
(insérer GIF + légende)
Nous introduisons un nouvel ensemble de domaines de tâches et d’ensembles de données associés avec un protocole d’évaluation clair. Nous incluons des domaines largement utilisés tels que DM Control Suite (Tassa et al., 2018) et les jeux Atari 2600 (Bellemare et al., 2013), mais aussi des domaines qui restent difficiles pour les algorithmes RL en ligne robustes tels que les tâches de groupe RL du monde réel (RWRL) (Dulac-Arnold et al., 2020) et les tâches DM Locomotion (Heess et al., 2017 ; Merel et al., 2019a, b, 2020). En normalisant les environnements, les ensembles de données et les protocoles d’évaluation, nous espérons rendre la recherche en RL hors ligne plus reproductible et accessible. Nous appelons notre ensemble de critères “RL Unplugged”, car les méthodes RL hors ligne peuvent être utilisées sans qu’aucun acteur n’interagisse avec l’environnement. Notre article apporte quatre contributions majeures : (1) une API unifiée pour les ensembles de données (2) une variété d’environnements (3) des protocoles d’évaluation clairs pour la recherche RL hors ligne et (4) des références de référence de performance.