
Construire des systèmes artificiels qui voient et reconnaissent le monde de la même manière que les systèmes visuels humains est un objectif majeur de la vision par ordinateur. Les progrès récents dans la mesure de l’activité cérébrale de la population, ainsi que les améliorations dans la mise en œuvre et la conception de modèles de réseaux de neurones profonds, ont permis de comparer directement les caractéristiques architecturales des réseaux synthétiques à celles des perceptions sous-jacentes des cerveaux biologiques, révélant des détails importants sur la façon dont ça arrive. les systèmes fonctionnent. La reconstruction d’images visuelles à partir de l’activité cérébrale, telles que celles détectées par l’imagerie par résonance magnétique fonctionnelle (IRMf), est l’une de ces applications. Il s’agit d’un problème fascinant mais difficile car les représentations sous-jacentes du cerveau sont largement inconnues et la taille de l’échantillon généralement utilisé pour les données cérébrales est petite.
Récemment, les universitaires ont utilisé des modèles et des techniques d’apprentissage en profondeur, tels que les réseaux antagonistes génératifs (GAN) et l’apprentissage auto-supervisé, pour relever ce défi. Cependant, ces investigations nécessitent soit de s’adapter aux stimuli particuliers utilisés dans l’expérience IRMf, soit de former de nouveaux paradigmes génératifs avec des données IRMf à partir de zéro. Ces tentatives ont montré des performances impressionnantes mais limitées en termes de résolution de pixels et de sémantique, en partie à cause de la faible quantité de données neuroscientifiques et en partie à cause des multiples difficultés associées à la construction de modèles de génération complexes.
Les modèles de diffusion, en particulier les modèles de diffusion latente les moins gourmands en ressources informatiques, sont une alternative récente au GAN. Cependant, le LDM étant encore relativement nouveau, il est difficile de bien comprendre son fonctionnement en interne.
En utilisant un LDM appelé Stable Diffusion pour reconstruire des images visuelles à partir de signaux IRMf, une équipe de recherche de l’Université d’Osaka et de CiNet a tenté de résoudre les problèmes ci-dessus. Ils ont proposé un cadre simple qui peut reconstruire des images haute résolution avec une fidélité sémantique élevée sans qu’il soit nécessaire de former ou d’ajuster des modèles complexes d’apprentissage en profondeur.
🔥 Lecture recommandée : Tirer parti de TensorLeap pour apprendre un transfert efficace : surmonter les lacunes sur le terrain
L’ensemble de données que les auteurs ont utilisé pour cette enquête est le Landscape Dataset (NSD), qui présente les données recueillies à partir d’un scanner IRMf sur 30 à 40 sessions au cours desquelles chaque sujet a vu trois répétitions de 10 000 images.
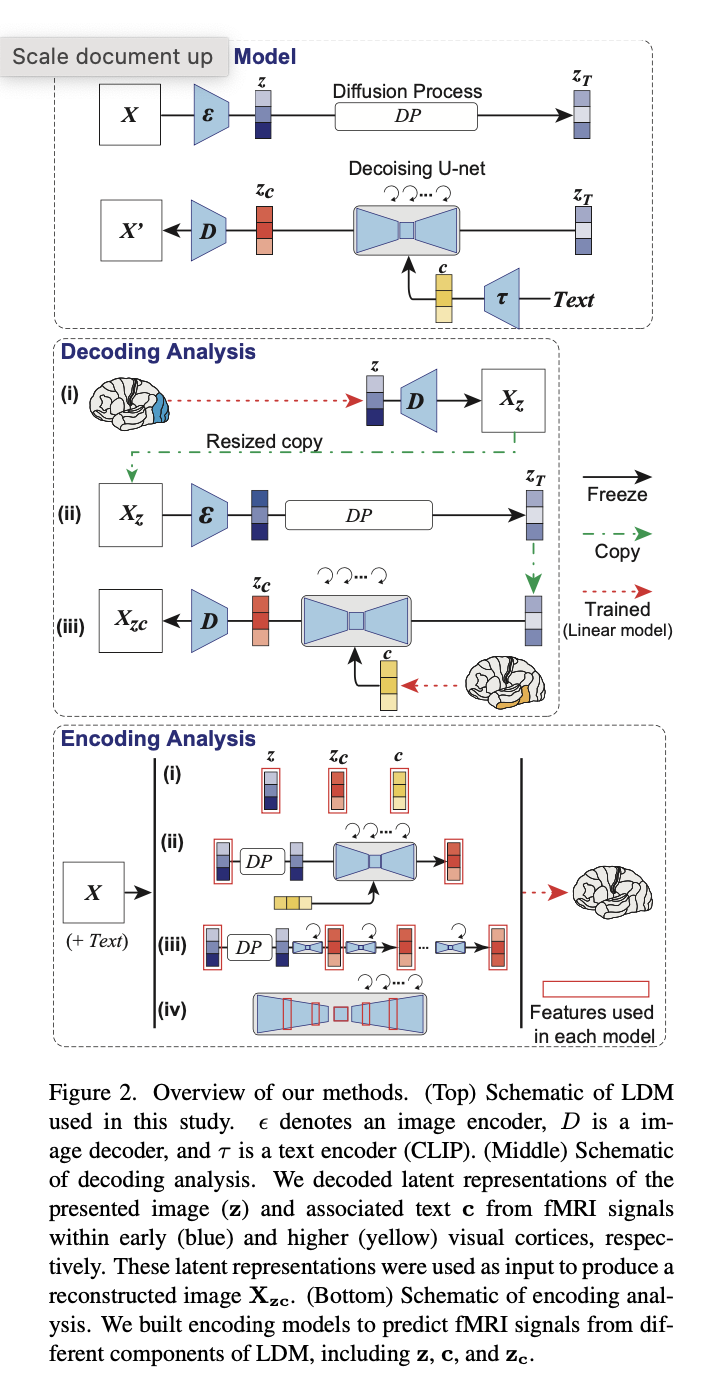
Pour commencer, ils ont utilisé le modèle de diffusion latente pour créer des images à partir de texte. Dans la figure ci-dessus (en haut), z est défini comme la représentation latente générée de z qui est modifiée par le modèle avec c, c est défini comme la représentation latente des textes (qui décrivent des images) et zc est défini comme la représentation latente de l’image originale compressée par l’auto-encodeur.
Pour analyser le modèle de décodage, les auteurs ont suivi trois étapes (figure ci-dessus, milieu). Tout d’abord, ils ont prédit une représentation z latente de l’image projetée en X à partir de signaux IRMf dans le cortex visuel précoce (bleu). z a ensuite été traité par un décodeur pour produire une image Xz décodée, qui a ensuite été codée et passée par le processus de diffusion. Enfin, l’image bruyante a été ajoutée à une représentation de transcription latente décodée à partir de signaux IRMf dans le cortex visuel supérieur (jaune) et superposée avec le bruit pour produire zc. A partir de là, le décodeur zc produit une image reconstruite finale Xzc. Il est important de souligner que la seule formation requise pour ce processus est la cartographie linéaire des signaux IRMf pour les composants LDM, zc, z et c.
En commençant par zc, z et c, les auteurs ont effectué une analyse de codage pour interpréter les processus internes de LDM en les mappant à l’activité cérébrale (figure ci-dessus, en bas). Les résultats de reconstruction d’image à partir des représentations sont présentés ci-dessous.

Les images simplement recréées avec z ont une cohérence visuelle avec les images originales, mais leur valeur sémantique est perdue. D’autre part, les images partiellement reconstruites avec c ont donné des images avec une grande précision sémantique mais une optique incohérente. Cette méthode est validée par la capacité des images récupérées avec zc à produire des images haute résolution avec une grande fidélité sémantique.
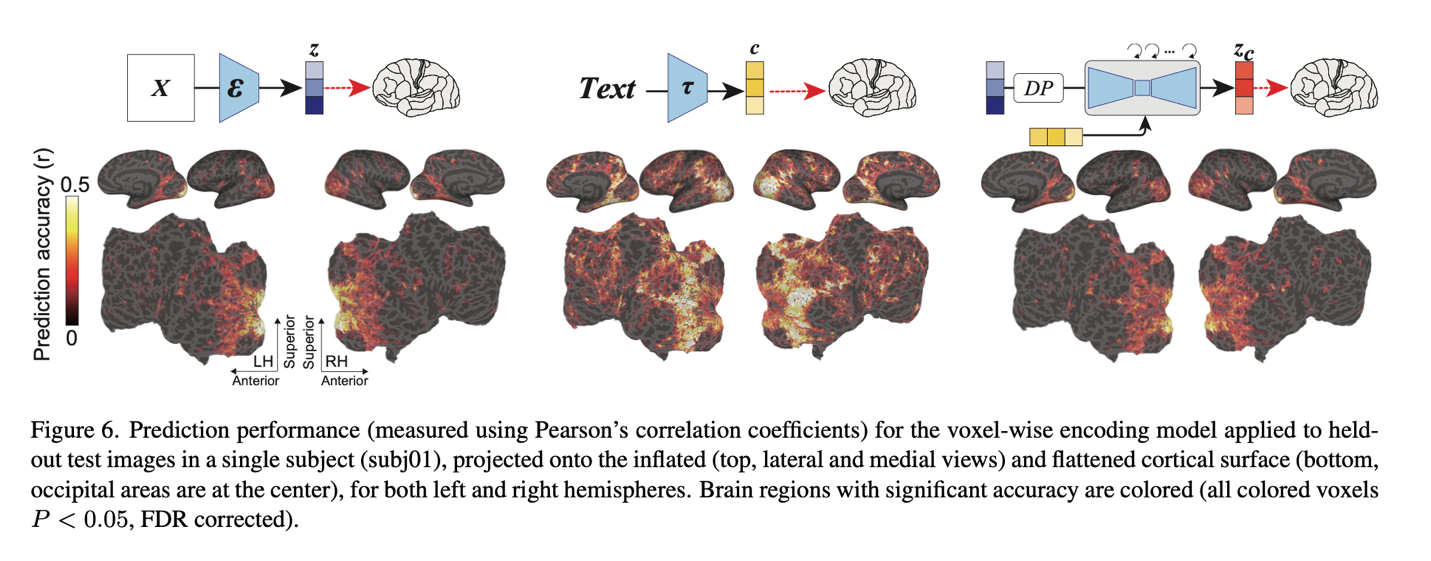
L’analyse finale du cerveau révèle de nouvelles informations sur les paradigmes du DM. À l’arrière du cerveau, le cortex visuel, les trois composants ont obtenu des résultats impressionnants en matière de prédiction. En particulier, z a fourni de fortes performances de prédiction dans le cortex visuel précoce, qui est situé dans la partie postérieure du cortex visuel. En outre, il a montré de fortes valeurs prédictives dans le cortex visuel supérieur, qui est la partie antérieure du cortex visuel, mais a montré des valeurs plus faibles dans les autres régions. En revanche, dans le cortex visuel supérieur, c a donné les meilleures performances de prédiction.
scanner le papier Et Page du projet. Tout le mérite de cette recherche revient aux chercheurs de ce projet. N’oubliez pas non plus de vous inscrire 16k + ML Sub RedditEt canal de discordeEt Courrieloù nous partageons les dernières nouvelles sur la recherche en IA, des projets d’IA sympas, et plus encore.
Leonardo Tanzi est actuellement titulaire d’un doctorat. Étudiant à l’Université Polytechnique de Turin, Italie. Ses recherches actuelles portent sur les méthodologies homme-machine pour un accompagnement intelligent lors d’interventions complexes dans le domaine médical, utilisant le deep learning et la réalité augmentée pour l’assistance 3D.