
L’apprentissage par renforcement fournit un cadre conceptuel permettant aux agents indépendants d’apprendre de l’expérience, de la même manière que vous entraînez un animal de compagnie pour recevoir des récompenses. Mais les applications pratiques de l’apprentissage par renforcement sont souvent distantes : au lieu d’utiliser RL pour apprendre par essais et erreurs en tentant réellement une tâche à accomplir, les implémentations typiques de RL utilisent une étape de formation distincte (généralement simulée). Par exemple, AlphaGo n’a pas appris à jouer au Go en affrontant des milliers d’humains, mais plutôt en jouant contre lui-même dans une simulation. Bien que ce type de formation simulée soit attrayant pour les jeux où les règles sont bien connues, son application à des domaines du monde réel tels que la robotique peut nécessiter une combinaison d’approches complexes, telles que l’utilisation de données simulées ou d’outils d’environnements réels dans divers moyens de rendre la formation possible dans des conditions de laboratoire. Pourrait-on plutôt imaginer des systèmes d’apprentissage par renforcement pour les robots qui leur permettent d’apprendre directement “sur le tas”, tout en effectuant la tâche qu’ils ont à faire ? Dans cet article de blog, nous discuterons de ReLMM, un système que nous avons développé et qui apprend à nettoyer une pièce directement avec un vrai robot via un apprentissage continu.




Nous évaluons notre méthode dans différentes tâches variant en difficulté. La tâche en haut à gauche a des points blancs uniformes pour une capture sans obstruction, tandis que d’autres pièces contiennent des objets de formes et de couleurs variées, des obstacles qui rendent difficile la navigation et le blocage des objets et des tapis à motifs qui rendent difficile la vue des objets sur le sol.
Pour permettre une formation “sur le tas” dans le monde réel, la difficulté d’accumuler plus d’expérience est prohibitive. Si nous pouvons faciliter la formation dans le monde réel, en rendant le processus de collecte de données plus autonome sans nécessiter de surveillance ou d’intervention humaine, nous pouvons bénéficier davantage de la simplicité des agents apprenant par l’expérience. Dans ce travail, nous concevons un système qui entraîne un robot mobile “sur le tas” pour le nettoyage en apprenant à saisir des objets dans différentes pièces.
Les gens ne sont pas nés un jour et interrogés le lendemain. Il existe de nombreux niveaux de tâches que les gens apprennent avant de postuler à un emploi. Nous commençons par les tâches les plus faciles et nous les développons. Chez ReLMM, nous tirons parti de ce concept en permettant aux robots de former des compétences réutilisables communes, telles que la préhension, en encourageant d’abord le robot à donner la priorité à la formation de ces compétences avant d’apprendre les compétences suivantes, telles que la mobilité. Apprendre de cette manière présente deux avantages pour les robots. Le premier avantage est que lorsqu’un agent se concentre sur l’apprentissage d’une compétence, il est plus efficace pour collecter des données sur la répartition locale de cette compétence dans le pays.
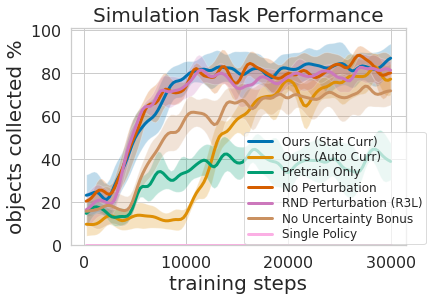
Ceci est illustré dans la figure ci-dessus, où nous avons évalué la quantité d’expérience de préhension prioritaire nécessaire pour obtenir une formation efficace sur la manipulation du téléphone mobile. Le deuxième avantage de l’approche d’apprentissage à plusieurs niveaux est que nous pouvons examiner les modèles entraînés sur différentes tâches et leur poser des questions telles que “Pouvez-vous comprendre quelque chose maintenant”, ce qui est utile pour la formation à la mobilité que nous décrivons ensuite.
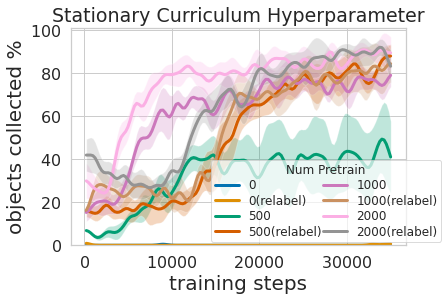
Non seulement la formation à cette politique à plusieurs niveaux était plus efficace que l’apprentissage des deux compétences en même temps, mais elle permettait au contrôleur de prise d’informer la politique de navigation. Avoir un modèle qui estime l’incertitude de son succès (pour nous ci-dessus) pour améliorer la navigation d’exploration en sautant les zones qui n’ont pas d’objets compréhensibles, contrairement Prime d’incertitude qui n’utilisent pas ces informations. Le modèle peut également être utilisé pour renommer des données pendant la formation de sorte que dans le cas malchanceux où le modèle de préhension n’a pas réussi à comprendre un objet à sa portée, la politique de préhension peut toujours fournir un signal en indiquant la présence d’un objet mais la préhension la politique n’a pas encore appris à le comprendre . De plus, l’apprentissage de modèles standard présente des avantages techniques. La formation modulaire permet la réutilisation de compétences faciles à apprendre et peut permettre de construire des systèmes intelligents pièce par pièce. Ceci est utile pour de nombreuses raisons, notamment pour évaluer et comprendre la sécurité.
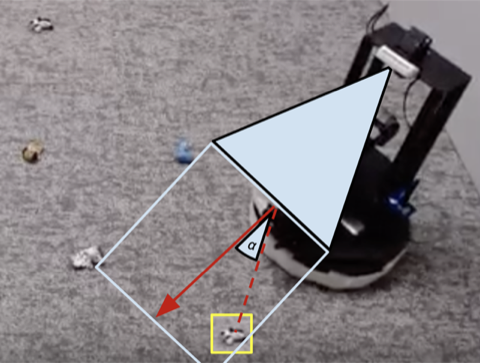
De nombreuses tâches robotiques que nous voyons aujourd’hui peuvent être résolues avec plus ou moins de succès à l’aide de contrôleurs fabriqués à la main. Pour notre tâche de nettoyage de chambre, nous avons conçu un contrôleur conçu à la main qui localise les objets à l’aide du regroupement d’images et se dirige vers l’objet détecté le plus proche à chaque étape. Le contrôleur conçu par des experts fonctionne très bien sur les chaussettes de balle visuellement accentuées et prend des chemins raisonnables autour des obstacles. Mais elle ne peut pas apprendre rapidement le chemin optimal pour collecter des objets et se débat avec des pièces visuellement diverses.. Comme le montre la vidéo 3 ci-dessous, la politique écrite est distraite par le tapis à motifs blancs tout en essayant de localiser plus d’objets blancs pour donner un sens.
1) 
2) 
3) 
4) 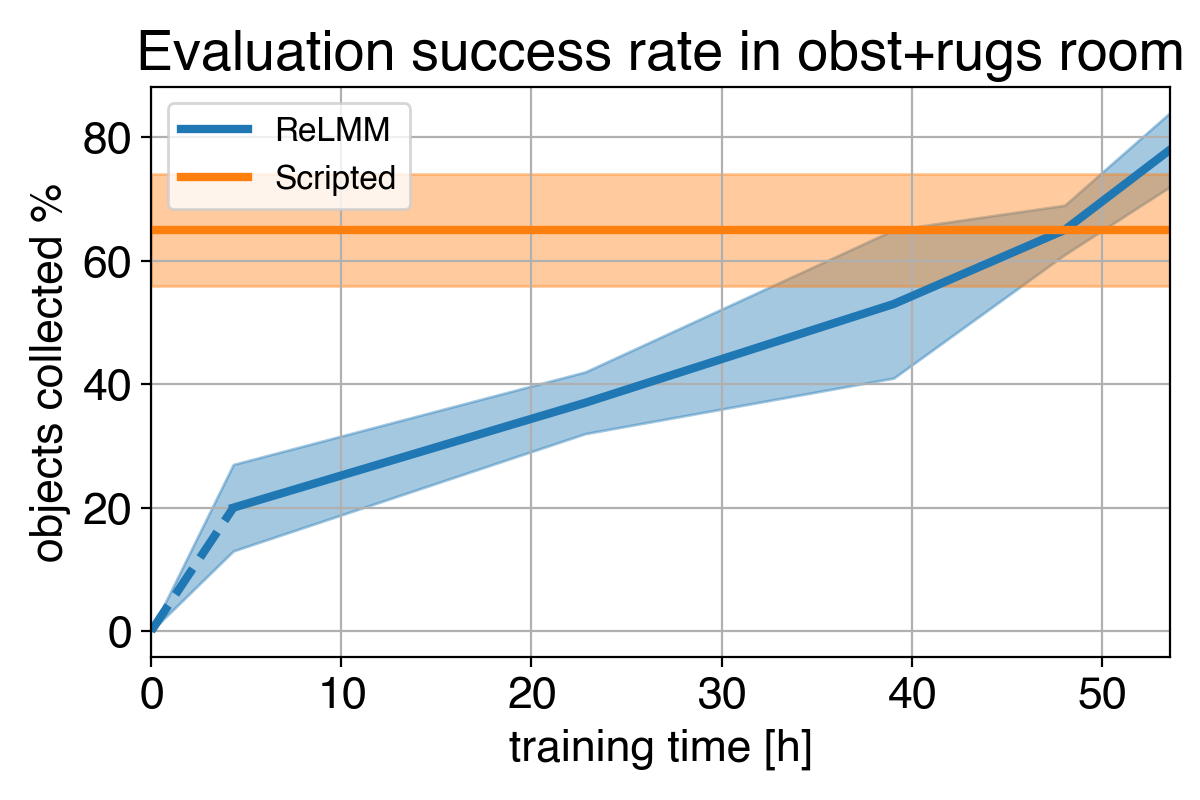
Nous montrons une comparaison de (1) notre politique au début de la formation (2) notre politique à la fin de la formation (3) la politique écrite. Dans (4), nous pouvons voir les performances du robot s’améliorer avec le temps, dépassant éventuellement la politique écrite de collecte rapide des objets dans la pièce.
Considérant que nous pouvons faire appel à des experts pour coder manuellement la console conçue, quel est le but de l’apprentissage ? Une limitation importante des contrôleurs fabriqués à la main est qu’ils sont réglés pour une tâche spécifique, par exemple, saisir des objets blancs. Lors de la présentation de divers objets dont la couleur et la forme diffèrent, le réglage d’origine peut ne pas être optimal. Au lieu de nécessiter plus d’ingénierie manuelle, notre méthode basée sur l’apprentissage est capable de s’adapter à différentes tâches en rassemblant sa propre expérience.
Cependant, la leçon la plus importante est que même si une console fabriquée à la main est capable, le facteur d’apprentissage finit par l’emporter si on lui donne suffisamment de temps. Ce processus d’apprentissage est autonome et se produit pendant que le robot fait son travail, ce qui le rend relativement peu coûteux. Cela démontre la capacité des agents d’apprentissage, qui peuvent également être considérés comme trouvant un moyen générique d’effectuer un “réglage manuel expert” pour tout type de tâche. Les systèmes d’apprentissage ont la capacité de créer l’intégralité de l’algorithme de contrôle du robot et ne se limitent pas à définir certains paramètres dans le script. Une étape clé de ce travail consiste à permettre à ces systèmes d’apprentissage du monde réel de collecter indépendamment les données nécessaires pour permettre le succès des méthodes d’apprentissage.
Cet article est basé sur l’article « Entirely Real-World Autonomous Reinforcement Learning Using Mobile Manipulation Applications », qui a été présenté à CoRL 2021. Vous pouvez trouver plus de détails dans notre article, sur notre site Web et dans la vidéo. Nous fournissons du code pour reproduire nos expériences. Nous remercions Sergey Levin pour ses précieux commentaires sur cet article de blog.