
DeepNash apprend à jouer à la stratégie à partir de zéro en combinant la théorie des jeux avec Deep RL sans modèle
Les systèmes d’intelligence artificielle (IA) qui jouent à des jeux ont évolué vers de nouveaux sommets. Stratego, le jeu de société classique qui est plus complexe que les échecs et va, et plus littéral que le poker, est maintenant maîtrisé. Publié dans Science, nous présentons Deb Nashun agent de l’IA qui a appris le jeu à partir de zéro au niveau d’un expert humain en jouant contre lui-même.
DeepNash utilise une nouvelle approche, basée sur la théorie des jeux et l’apprentissage par renforcement profond sans modèle. Son style de jeu converge avec Nash Balance, ce qui signifie qu’il est très difficile pour un adversaire de l’exploiter. Si difficile, en fait, que DeepNash a atteint un niveau record de trois rangs parmi les experts humains sur la plus grande plateforme de stratégie en ligne au monde, Gravon.
Les jeux de société sont depuis longtemps une mesure de progrès dans le domaine de l’intelligence artificielle, permettant d’étudier comment les humains et les machines développent et mettent en œuvre des stratégies dans un environnement contrôlé. Contrairement à Chess and Go, Stratego est un jeu d’informations imparfaites : les joueurs ne peuvent pas observer directement l’identité des pièces de leur adversaire.
Cette complexité signifie que d’autres systèmes stratégiques basés sur l’intelligence artificielle ont connu des difficultés au-delà du niveau amateur. Cela signifie également qu’une technique d’IA réussie appelée “recherche d’arbre de jeu”, qui a déjà été utilisée pour perfectionner de nombreux jeux avec des informations parfaites, n’est pas suffisamment évolutive pour Stratego. Pour cette raison, DeepNash va au-delà de la recherche de l’arbre du jeu.
La valeur de la maîtrise stratégique va au-delà des jeux vidéo. Dans la poursuite de notre mission de résoudre les problèmes d’intelligence pour faire avancer la science et profiter à l’humanité, nous devons construire des systèmes d’IA avancés qui peuvent fonctionner dans des situations complexes du monde réel avec des informations limitées sur les agents et les autres personnes. Notre article montre comment DeepNash peut être appliqué dans des situations d’incertitude et équilibrer les résultats avec succès pour aider à résoudre des problèmes complexes.
Découvrez Strago
Stratego est un jeu de capture de drapeau au tour par tour. C’est un jeu de tromperie, de tactique, de collecte de renseignements et de manœuvres furtives. C’est un jeu à somme nulle, donc toute victoire d’un joueur est une perte de taille égale pour son adversaire.
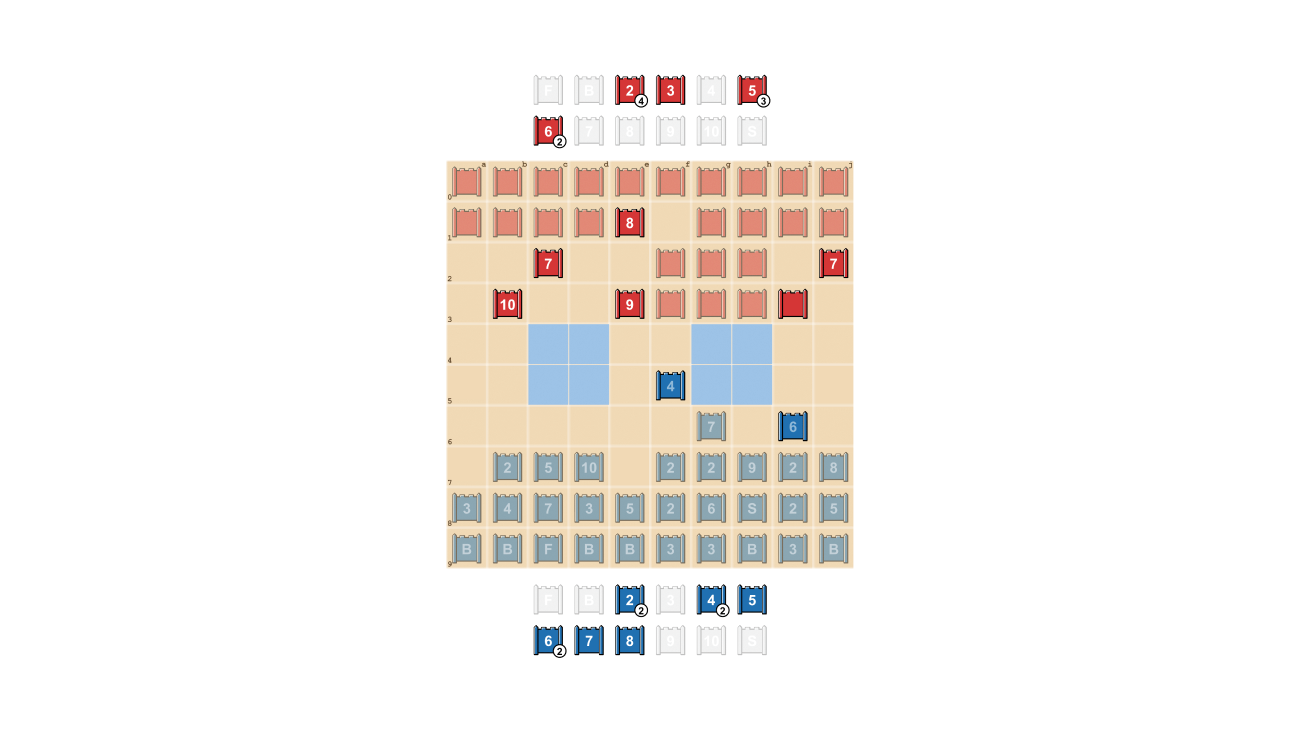
La stratégie est un défi pour l’IA, en partie parce que c’est un jeu avec des informations incomplètes. Les deux joueurs commencent par organiser leurs 40 pièces de jeu dans la formation de départ de leur choix, en se cachant d’abord l’un de l’autre au début de la partie. Étant donné que les deux acteurs n’ont pas accès aux mêmes connaissances, ils doivent peser tous les résultats possibles lors de la prise de décision, ce qui constitue un critère difficile pour examiner les interactions stratégiques. Les types de pièces et leur disposition sont indiqués ci-dessous.

milieu: Formation de départ possible. Remarquez comment le drapeau est caché en toute sécurité à l’arrière, flanqué de bombes flanquantes. Les deux zones bleu pâle sont des “lacs” et n’ont jamais été pénétrées.
Droite: Un jeu de course, montrant Blue’s Spy attrapant Red’s 10.
Obtenez des informations durement acquises chez Stratego. L’identité d’une pièce adverse n’est généralement révélée que lorsqu’elle rencontre l’autre joueur sur le champ de bataille. Cela contraste fortement avec les jeux d’information parfaits comme les échecs ou le go, où l’emplacement et l’identité de chaque pièce sont connus des deux joueurs.
Les méthodes d’apprentissage automatique qui fonctionnent bien avec les jeux optimisés pour les informations, comme AlphaZero de DeepMind, ne sont pas facilement transférées vers Stratego. La nécessité de prendre des décisions avec des informations incomplètes, et la possibilité de bluffer, rapproche Stratego du poker Texas Hold’em et nécessite une capacité humaine une fois noté par l’écrivain américain Jack London : « La vie n’est pas toujours une question de bonnes cartes. , mais parfois, jouer une bonne main.” “.
Cependant, les techniques d’IA qui fonctionnent si bien dans des jeux comme le Texas Hold’em ne sont pas transférées à Stratego, en raison de la durée du jeu – souvent des centaines de coups avant qu’un joueur ne gagne. La stratégie doit être pensée sur un grand nombre d’actions séquentielles sans vision claire de la façon dont chaque action contribue au résultat final.
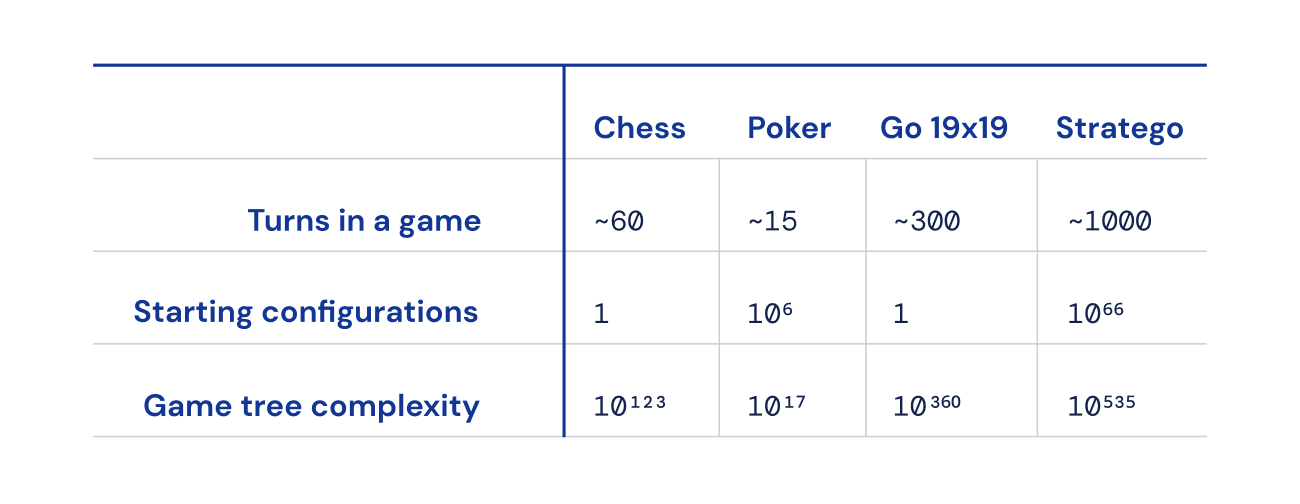
Enfin, le nombre d’états de jeu possibles (exprimé en “complexité de l’arbre de jeu”) est hors du graphique par rapport aux échecs, au go et au poker, ce qui le rend très difficile à résoudre. C’est ce qui nous rend si enthousiastes à propos de Stratego, et pourquoi il a présenté un défi vieux de plusieurs décennies à la communauté de l’IA.
La recherche de l’équilibre
DeepNash utilise une nouvelle approche basée sur une combinaison de théorie des jeux et d’apprentissage par renforcement profond et sans modèle. “Sans modèle” signifie que DeepNash n’essaie pas de modéliser explicitement l’état de jeu de son adversaire pendant une partie. Particulièrement dans les premières étapes du jeu, lorsque DeepNash en sait peu sur les pièces de l’adversaire, de tels modèles seraient inefficaces, voire impossibles.
Et parce que la complexité de l’arbre de jeu de Stratego est si vaste, DeepNash ne peut pas utiliser une approche puissante des jeux basés sur l’IA – la recherche d’arbre de Monte Carlo. La recherche sur les arbres a été un élément clé de nombreuses réalisations exceptionnelles en intelligence artificielle pour les jeux de table et le poker moins complexes.
Au lieu de cela, DeepNash est alimenté par une nouvelle idée d’algorithme de théorie des jeux que nous appelons Regularized Nash Dynamics (R-NaD). R-NaD fonctionne à une échelle inégalée et oriente le comportement d’apprentissage de DeepNash vers ce que l’on appelle un équilibre de Nash (plongez dans les détails techniques dans notre article).
Le comportement de jeu qui aboutit à l’équilibre de Nash n’est pas exploitable dans le temps. Si une personne ou une machine joue une stratégie complètement inexploitable, le pire taux de victoire qu’elle peut obtenir sera de 50 %, et seulement si elle rencontre un adversaire tout aussi parfait.
Dans les matchs contre les meilleurs robots de stratégie – dont de nombreux vainqueurs du championnat du monde de stratégie informatique – le taux de victoire de DeepNash dépasse 97 %, et il était souvent de 100 %. Contre les meilleurs joueurs humains experts de la plate-forme de jeu Gravon, DeepNash a un taux de victoire de 84%, ce qui le classe au troisième rang de tous les temps.
Attendez-vous à l’inattendu
Pour obtenir ces résultats, DeepNash a montré un comportement impressionnant à la fois pendant sa phase initiale de déploiement de pièces et pendant la phase de jeu. Afin de le rendre plus difficile à exploiter, DeepNash a développé une stratégie inattendue. Cela signifie créer des déploiements initiaux suffisamment diversifiés pour empêcher l’adversaire de repérer des modèles au cours d’une série de jeux. Et pendant la phase de jeu, DeepNash randomise les actions entre des actions apparemment équivalentes pour empêcher les tendances exploitables.
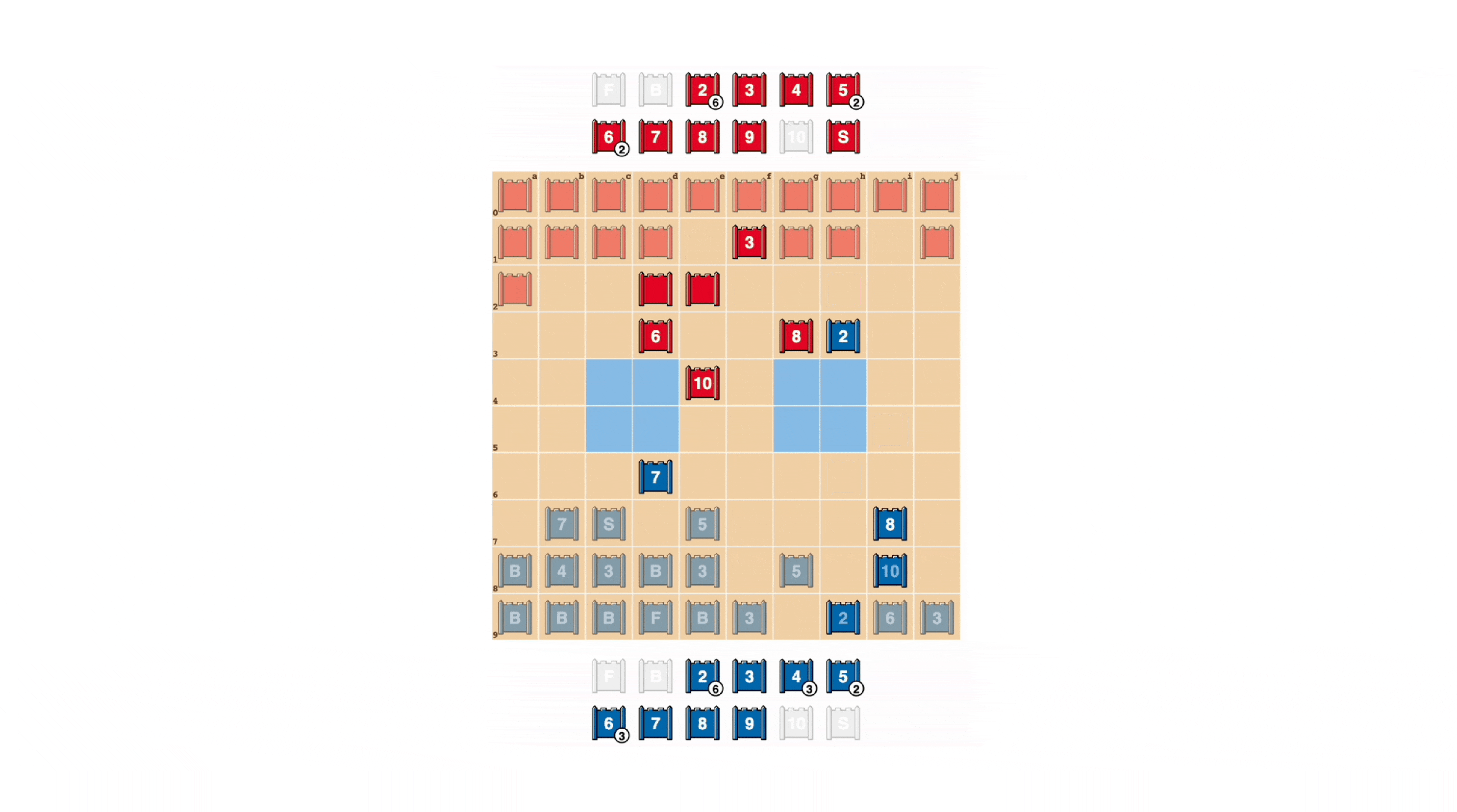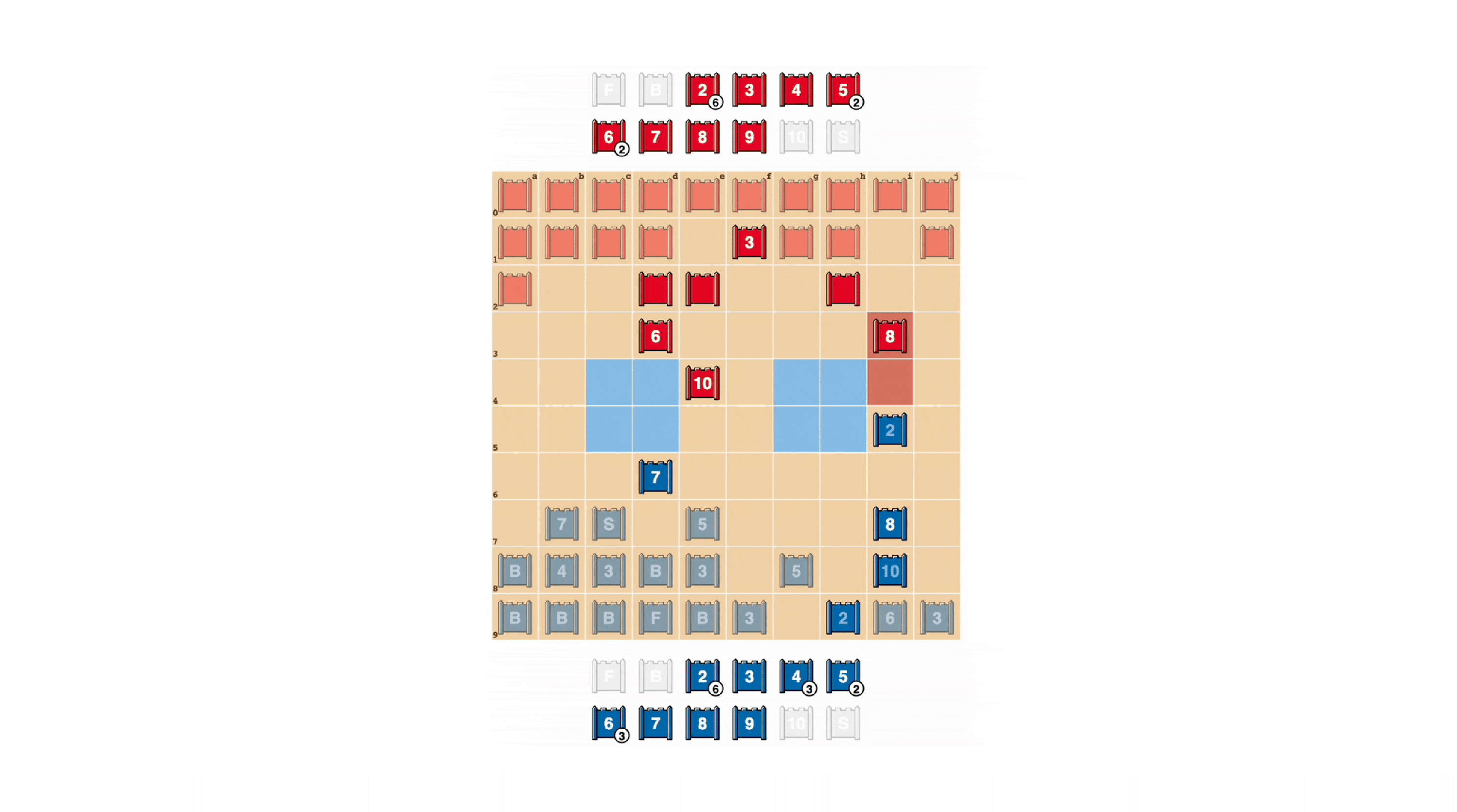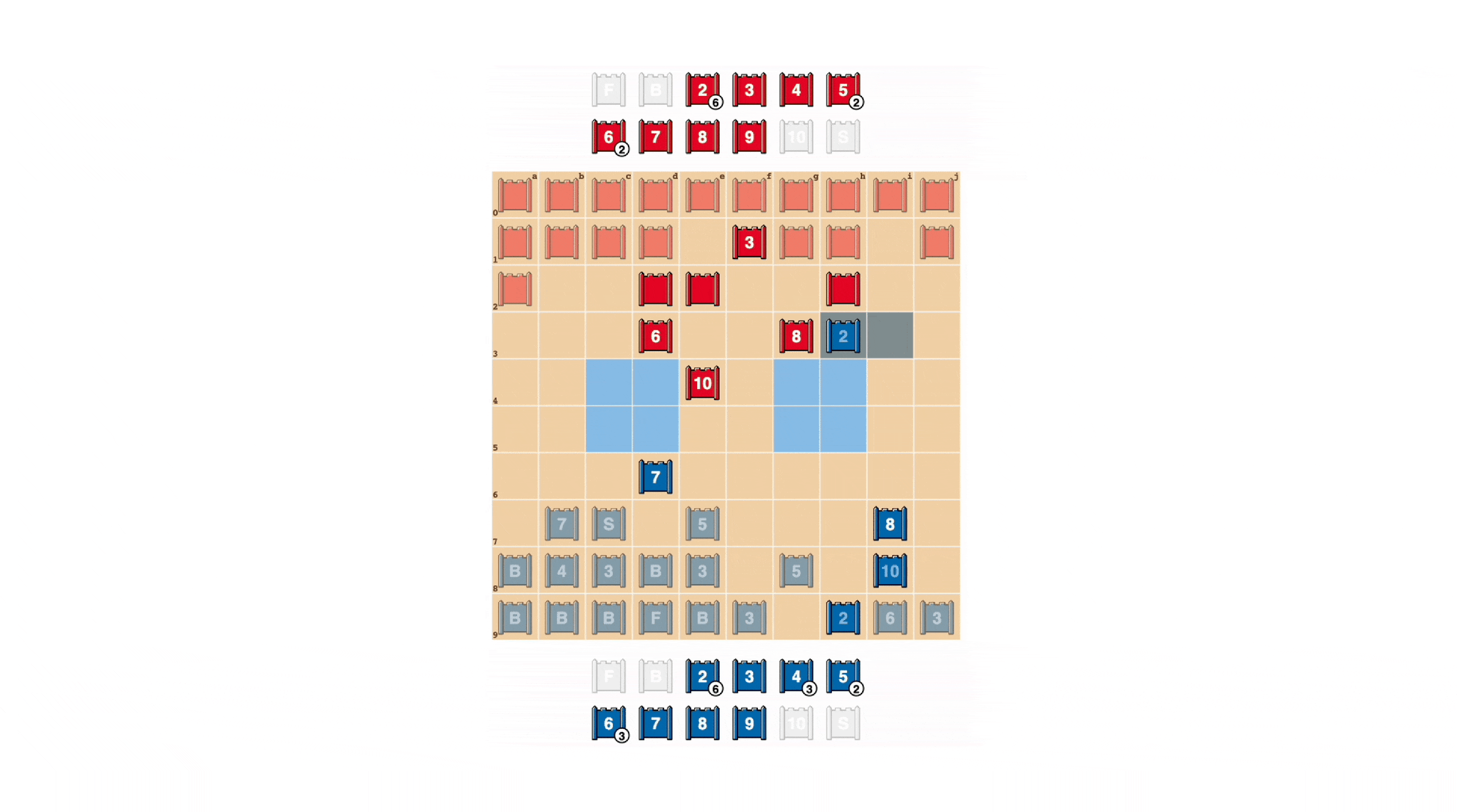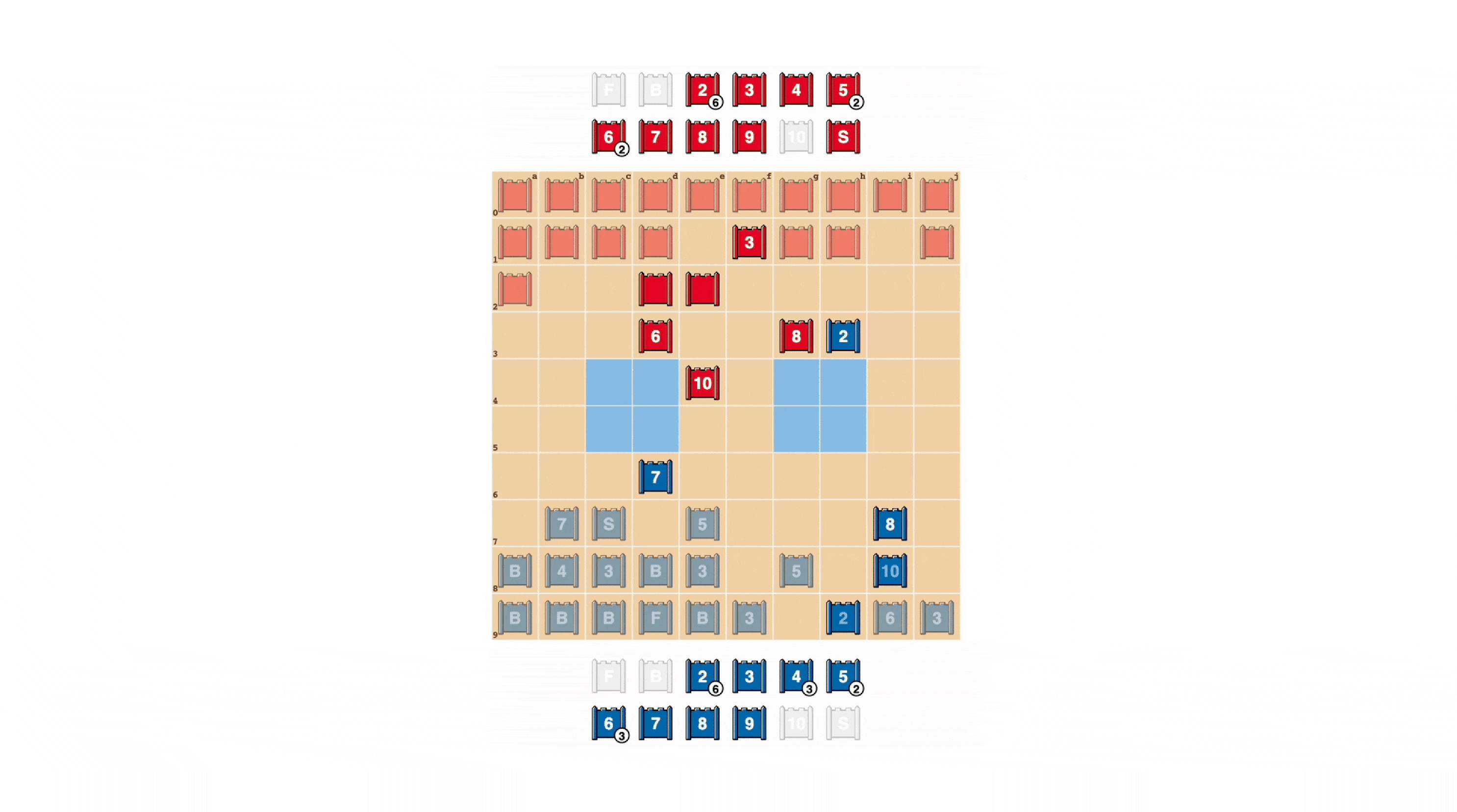
Les stratèges s’efforcent d’être imprévisibles, il est donc utile de cacher des informations. DeepNash montre comment vous valorisez les informations de manière absolument incroyable. Dans l’exemple ci-dessous, contre un joueur humain, DeepNash (Bleu) a sacrifié, entre autres, 7 (Major) et 8 (Colonel) en début de partie et a ainsi pu localiser le 10 (Marshal) de l’adversaire, 9 ( général) , 8 et 7.
Ces efforts ont laissé DeepNash dans une situation financière défavorable. Elle perd 7 et 8 tandis que son adversaire humain garde toutes ses pièces à 7 et plus. Cependant, parce qu’il disposait d’informations solides sur les meilleurs frappeurs des concurrents, DeepNash a estimé ses chances de gagner à 70% – et a gagné.
L’art de tromper
Comme au poker, un bon stratège doit parfois représenter la force, même lorsqu’il est faible. DeepNash a appris une variété de ces tactiques de phishing. Dans l’exemple ci-dessous, DeepNash utilise 2 (éclaireur faible, inconnu de son adversaire) comme s’il était une pièce de haut rang, poursuivant son adversaire connu 8. L’adversaire humain décide que le poursuivant est très probablement un 10, et essaie donc pour l’attirer dans une embuscade par leur espion. Cette tactique de DeepNash, ne risquant qu’une petite pièce, réussit à disposer et à éliminer l’espion de son adversaire, une pièce cruciale.
Voyez plus en regardant ces 4 vidéos de jeux complets auxquels DeepNash joue contre des experts humains (anonymes) : Jeu 1, Jeu 2, Jeu 3, Jeu 4.
“Le niveau de jeu sur DeepNash m’a surpris. Je n’ai jamais entendu parler d’un stratège industriel qui se soit approché du niveau requis pour gagner un match contre un joueur humain expérimenté. Mais après avoir moi-même joué contre DeepNash, je n’ai pas été surpris par le troisième rang qu’il a ensuite atteint sur la plate-forme Gravon. Je m’attends à ce qu’elle se comporte très bien si elle est autorisée à participer au Tournoi mondial des mortels.
– Vincent de Boer, co-auteur de recherche et ancien champion du monde de stratégie
directions futures
Alors que nous avons développé DeepNash pour le monde très spécifique de la stratégie, notre nouvelle méthode R-NaD peut être directement appliquée à d’autres jeux à somme nulle pour les joueurs qui contiennent des informations parfaites ou imparfaites. R-NaD a la capacité de généraliser au-delà des paramètres de jeu à deux joueurs pour résoudre des problèmes du monde réel à grande échelle, qui sont souvent caractérisés par des informations incomplètes et des espaces d’état astronomiques.
Nous espérons également que R-NaD aidera à ouvrir de nouvelles applications de l’IA dans des domaines qui comportent un grand nombre de participants humains ou d’IA avec des objectifs différents qui peuvent ne pas, comme dans le cas de grande échelle, contenir des informations sur l’intention des autres ou ce qui se passe dans leur environnement. Amélioration de la gestion du trafic pour réduire les temps de trajet des conducteurs et les émissions associées des véhicules.
En créant un système d’IA généralisable et robuste face à l’incertitude, nous espérons transférer les capacités de résolution de problèmes de l’IA dans notre monde intrinsèquement imprévisible.
Apprenez-en plus sur DeepNash en lisant notre article dans Science.
Pour les chercheurs intéressés à expérimenter R-NaD ou à travailler avec notre méthode nouvellement proposée, nous avons ouvert notre code.