
Le changement climatique de la Terre présente un risque accru de sécheresse en raison du réchauffement climatique. Depuis 1880, la température mondiale a augmenté de 1,01°C. Depuis 1993, le niveau de la mer a augmenté de 102,5 mm. Depuis 2002, la calotte glaciaire de l’Antarctique a perdu de la masse à un rythme de 151,0 milliards de tonnes métriques par an. En 2022, l’atmosphère terrestre contient plus de 400 parties par million (ppm) de dioxyde de carbone, soit 50 % de plus qu’en 1750. Bien que ces chiffres puissent sembler éloignés de notre vie quotidienne, la température de la Terre a augmenté à un niveau sans précédent. taux tout au long de l’année. les 10 000 dernières années (1).
Dans cet article, nous utilisons les nouvelles capacités géospatiales d’Amazon SageMaker pour surveiller les sécheresses causées par le changement climatique au lac Mead. Le lac Mead est le plus grand réservoir des États-Unis. Il alimente en eau 25 millions de personnes dans les États du Nevada, de l’Arizona et de la Californie (2). Les recherches montrent que les niveaux d’eau du lac Mead sont à leur plus bas depuis 1937 (3). Nous utilisons les capacités géospatiales de SageMaker pour mesurer les changements des niveaux d’eau dans le lac Mead à l’aide d’images satellites.
La saisie des données
Les nouvelles fonctionnalités géospatiales de SageMaker permettent d’accéder facilement aux données géospatiales telles que Sentinel-2 et Landsat 8. L’accès intégré aux ensembles de données géospatiales permet d’économiser des semaines d’efforts inutiles à collecter des données auprès de divers fournisseurs et fournisseurs de données.
Tout d’abord, nous allons utiliser un bloc-notes Amazon SageMaker Studio avec une image géospatiale SageMaker en suivant les étapes décrites dans Mise en route avec les capacités géospatiales d’Amazon SageMaker. Nous utilisons un bloc-notes SageMaker Studio avec une image géospatiale SageMaker pour notre analyse.
Le bloc-notes utilisé dans cet article se trouve dans le référentiel GitHub amazon-sagemaker-amples. SageMaker Geospatial facilite l’interrogation des données. Nous utiliserons le code suivant pour déterminer l’emplacement et la période des données satellitaires.
Dans l’extrait de code suivant, nous définissons d’abord un fichier AreaOfInterest (AOI) avec une boîte englobante autour de la région du lac Mead. Nous utilisons le TimeRangeFilter Pour sélectionner des données de janvier 2021 à juillet 2022. Cependant, les nuages peuvent obscurcir la zone que nous étudions. Pour les images principalement sans nuages, nous sélectionnons un sous-ensemble d’images en fixant la limite supérieure de la couverture nuageuse à 1 %.
modèle d’inférence
Après avoir sélectionné les données, l’étape suivante consiste à extraire les masses d’eau de l’imagerie satellitaire. Habituellement, nous devons former un modèle de fragmentation de la couverture terrestre à partir de zéro pour identifier différentes classes de matériaux physiques à la surface de la Terre, tels que les masses d’eau, la végétation, la neige, etc. La formation d’un modèle à partir de zéro prend du temps et coûte cher. Inclut le balisage des données, la formation des modèles et le déploiement. Les capacités géospatiales de SageMaker fournissent un modèle de segmentation de la couverture terrestre pré-formé. Le modèle de segmentation de la couverture terrestre peut être exécuté avec un simple appel d’API.
Au lieu de télécharger les données sur une machine locale pour les inférences, SageMaker fait tout le gros du travail pour vous. Nous définissons simplement la configuration des données et la configuration du modèle dans la mission d’observation de la Terre (EOJ). SageMaker télécharge et prétraite automatiquement les données d’images satellites, les préparant pour l’inférence. Ensuite, SageMaker exécute automatiquement l’inférence du modèle EOJ. En fonction de la charge de travail (combien d’images sont exécutées via l’inférence de modèle), l’EOJ peut prendre plusieurs minutes à quelques heures pour se terminer. Vous pouvez surveiller l’état du travail avec un fichier get_earth_observation_job emploi.
Visualisez les résultats
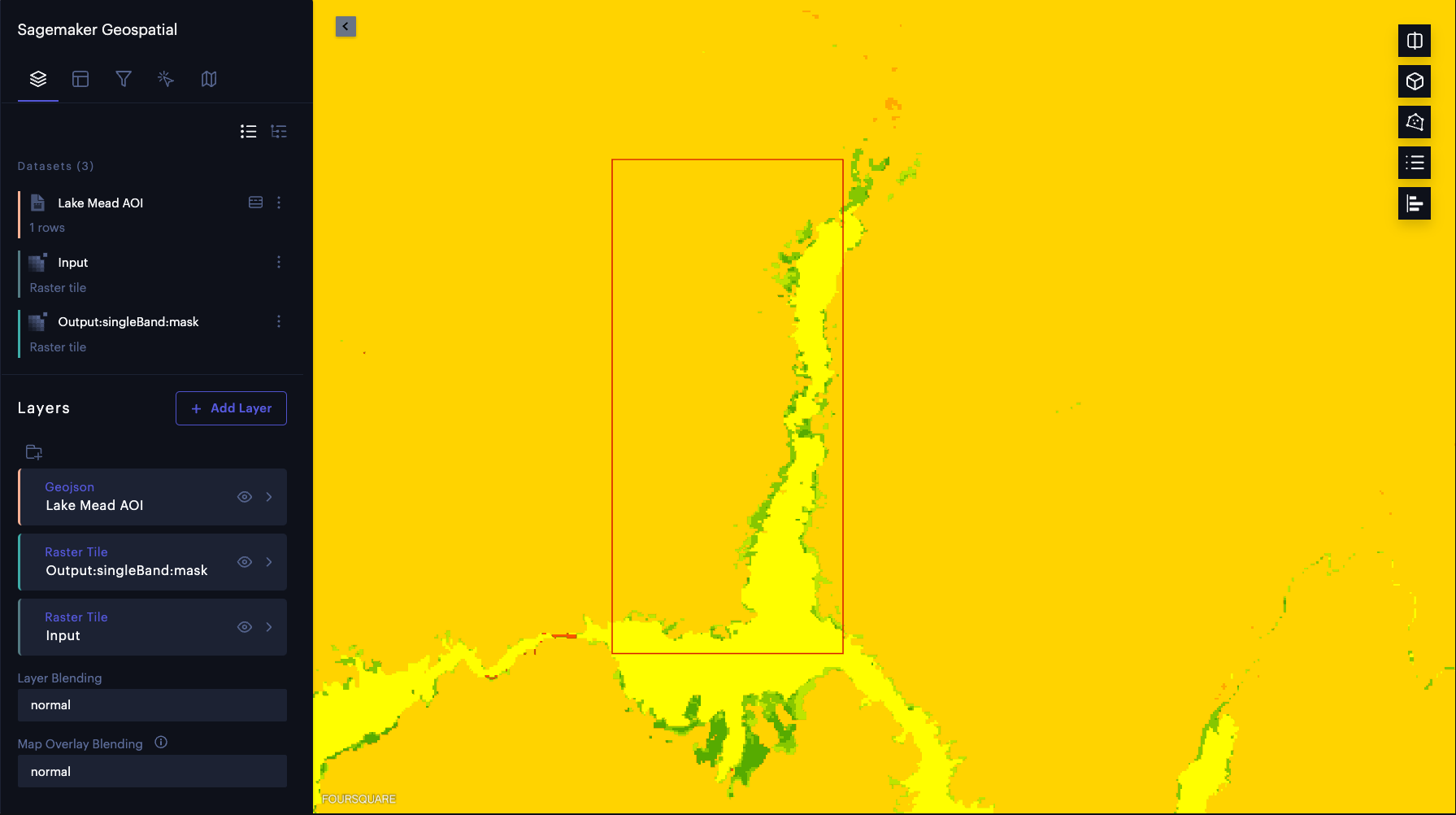
Maintenant que nous avons exécuté l’inférence d’échantillon, examinons visuellement les résultats. Nous superposons les résultats d’inférence du modèle sur les images satellites d’entrée. Nous utilisons les outils Foursquare Studio pré-intégrés à SageMaker pour visualiser ces résultats. Tout d’abord, nous créons une instance de carte à l’aide des capacités géospatiales de SageMaker pour visualiser les images d’entrée et les prédictions du modèle :
Lorsque la carte interactive est prête, nous pouvons restituer les images d’entrée et de sortie du modèle sous forme de couches de carte sans avoir à télécharger les données. De plus, nous pouvons donner à chaque couche une étiquette et spécifier les données pour une date spécifique en utilisant TimeRangeFilter:
Nous pouvons vérifier que la zone marquée par l’eau (jaune clair dans la carte suivante) correspond précisément à la masse d’eau du lac Mead en modifiant l’opacité du calque résultant.
post-analyse
Ensuite, nous utilisons un fichier export_earth_observation_job Fonction permettant d’exporter les résultats EOJ vers un compartiment Amazon Simple Storage Service (Amazon S3). Nous effectuons ensuite une post-analyse des données dans Amazon S3 pour calculer la surface de l’eau. La fonctionnalité d’exportation facilite le partage des résultats entre les équipes. SageMaker simplifie également la gestion de la collecte de données. Nous pouvons simplement partager les résultats EOJ à l’aide de la fonction ARN, au lieu d’explorer des milliers de fichiers dans un compartiment S3. Chaque EOJ devient un atout dans le catalogue de données, où les résultats peuvent être regroupés par fonction ARN.
Ensuite, nous analysons les changements du niveau d’eau dans le lac Mead. Nous téléchargeons des masques de couverture terrestre sur notre copie locale pour calculer la surface de l’eau à l’aide de bibliothèques open source. SageMaker enregistre la sortie du modèle au format Cloud Optimized GeoTiff (COG). Dans cet exemple, nous chargeons ces masques sous forme de tableaux NumPy à l’aide du package Tifffile. faiseur sage Geospatial 1.0 Le noyau comprend également d’autres bibliothèques largement utilisées telles que GDAL et Rasterio.
Chaque pixel du masque de couverture du sol a une valeur comprise entre 0 et 11. Chaque valeur correspond à une classe spécifique d’occupation du sol. L’indice de classe d’eau est 6. Nous pouvons utiliser cet indice de classe pour extraire le masque d’eau. Tout d’abord, nous comptons le nombre de pixels marqués comme de l’eau. Ensuite, nous multiplions ce nombre par la surface couverte par chaque pixel pour obtenir la surface de l’eau. Selon les bandes, la résolution spatiale de l’image Sentinel-2 L2A est de 10M20Mou 60M. Toutes les échelles sont réduites à une résolution spatiale de 60 m pour l’inférence du modèle de fragmentation de la couverture terrestre. En conséquence, chaque pixel du masque d’occupation du sol représente une superficie terrestre de 3600 M2soit 0,0036 combien2.
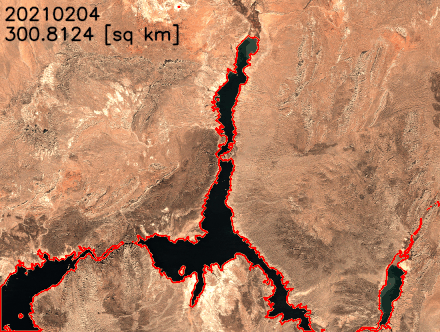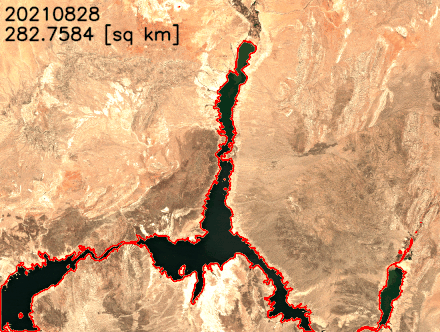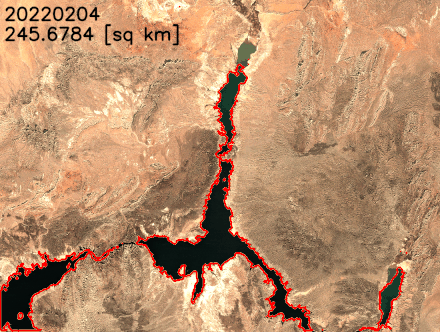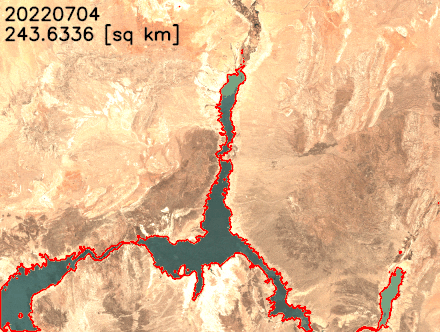
Nous traçons la surface de l’eau au fil du temps dans la figure suivante. La superficie de l’eau a visiblement diminué entre février 2021 et juillet 2022. En moins de deux ans, la superficie du lac Mead est passée de plus de 300 combien2 à moins de 250 combien2changement relatif de 18 %.
 ')
')Nous pouvons également extraire les limites des lacs et les superposer aux images satellites pour mieux visualiser les changements de la côte du lac. Comme le montre l’animation suivante, le littoral nord et sud-est s’est rétréci au cours des deux dernières années. En certains mois, la superficie a diminué de plus de 20 % d’une année sur l’autre.
Conclusion
Nous avons vu l’impact du changement climatique sur le rétrécissement du littoral du lac Mead. SageMaker prend désormais en charge l’apprentissage automatique géospatial (ML), ce qui permet aux scientifiques des données et aux ingénieurs en apprentissage automatique de créer, former et déployer plus facilement des modèles à l’aide de données géospatiales. Dans cet article, nous expliquons comment acquérir des données, effectuer des analyses et visualiser les modifications à l’aide des services SageMaker Geospatial AI/ML. Vous pouvez trouver le code de cet article dans le référentiel GitHub amazon-sagemaker-amples. Consultez les capacités géospatiales d’Amazon SageMaker pour en savoir plus.
Les références
(1) https://climate.nasa.gov/
(2) https://www.nps.gov/lake/learn/nature/overview-of-lake-mead.htm
(3) https://earthobservatory.nasa.gov/images/150111/lake-mead-keeps-dropping
À propos des auteurs
Xiong Chu Il est scientifique d’application senior chez AWS. Dirige l’équipe scientifique pour les capacités géospatiales d’Amazon SageMaker. Son domaine de recherche actuel comprend la vision par ordinateur et la formation de modèles actifs. Dans ses temps libres, il aime courir, jouer au basket et passer du temps avec sa famille.
Anirudh Viswanathan Il est chef de produit senior, technique – services d’externalisation au sein de l’équipe SageMaker geospatial ML. Il est titulaire d’une maîtrise en robotique de l’Université Carnegie Mellon, d’un MBA de la Wharton School of Business et est l’inventeur de plus de 40 brevets. Il aime courir sur de longues distances, visiter des galeries d’art et des spectacles à Broadway.
Peigne à lèvres de Trenton Il est architecte principal et fait partie de l’équipe qui a ajouté des capacités géospatiales à SageMaker. Il a été impliqué dans des solutions humaines en boucle, travaillant sur les services SageMaker Ground Truth, Augmented AI et Amazon Mechanical Turk.
Xingjian Shi Il est un scientifique d’application senior et fait partie de l’équipe qui a ajouté des capacités géospatiales à SageMaker. Il travaille également sur l’apprentissage profond pour les géosciences et l’AutoML multimédia.
Lee Iran Lee Il est directeur des sciences appliquées aux services humains chez Loop, AWS AI, Amazon. Ses intérêts de recherche sont l’apprentissage profond 3D, l’apprentissage de la vision et la représentation du langage. Il était auparavant scientifique principal chez Alexa AI, responsable de l’apprentissage automatique chez Scale AI et scientifique en chef chez Pony.ai. Auparavant, il faisait partie de l’équipe Cognition d’Uber ATG et de l’équipe Machine Learning Platform d’Uber, travaillant sur l’apprentissage automatique pour la conduite autonome, les systèmes d’apprentissage automatique et les initiatives stratégiques d’IA. Il a commencé sa carrière chez Bell Labs et a été professeur auxiliaire à l’Université de Columbia. Co-enseignant à ICML’17 et ICCV’19, et co-animateur de plusieurs ateliers NeurIPS, ICML, CVPR et ICCV sur l’apprentissage automatique pour la conduite autonome, la vision 3D, la robotique, les systèmes d’apprentissage automatique et l’apprentissage automatique contradictoire. Il est titulaire d’un doctorat en informatique de l’Université Cornell. Il est membre ACM et membre IEEE.