
En général, les objectifs de haut niveau d’Acme sont les suivants :
- Pour permettre la reproduction de nos méthodes et résultats – cela aidera à montrer ce qui rend un problème RL difficile ou facile, quelque chose qui est rarement évident.
- Pour simplifier la façon dont nous (et la communauté dans son ensemble) concevons de nouveaux algorithmes – nous voulons que notre prochain proxy RL soit plus facile à écrire pour tout le monde !
- Pour améliorer la lisibilité des agents RL, il ne devrait y avoir aucune surprise cachée lors du passage de la feuille au code.
Afin d’atteindre ces objectifs, la conception d’Acme comble également le fossé entre les expériences à grande, moyenne et petite échelle. Nous y sommes parvenus en examinant attentivement la conception des agents à différentes échelles.
Au plus haut niveau, nous pouvons considérer Acme comme une interface RL classique (que l’on trouve dans n’importe quel texte d’introduction RL) qui connecte un acteur (c’est-à-dire un agent de sélection d’action) à l’environnement. Cet acteur est une interface simple qui permet de choisir des actions, de prendre des notes et de se mettre à jour. En interne, les agents d’apprentissage ont également divisé le problème en composants « action » et « apprentissage à partir des données ». Apparemment, cela nous permet de réutiliser des parties de la représentation à travers de nombreux opérateurs différents. Cependant, plus important encore, cela fournit une frontière décisive sur laquelle le processus d’apprentissage peut être divisé et équilibré. Nous pouvons même réduire à partir d’ici et attaquer de manière transparente le paramètre RL par lots là où il se trouve pas d’environnement et un ensemble de données statiques uniquement. Des illustrations de ces différents niveaux de complexité sont données ci-dessous :
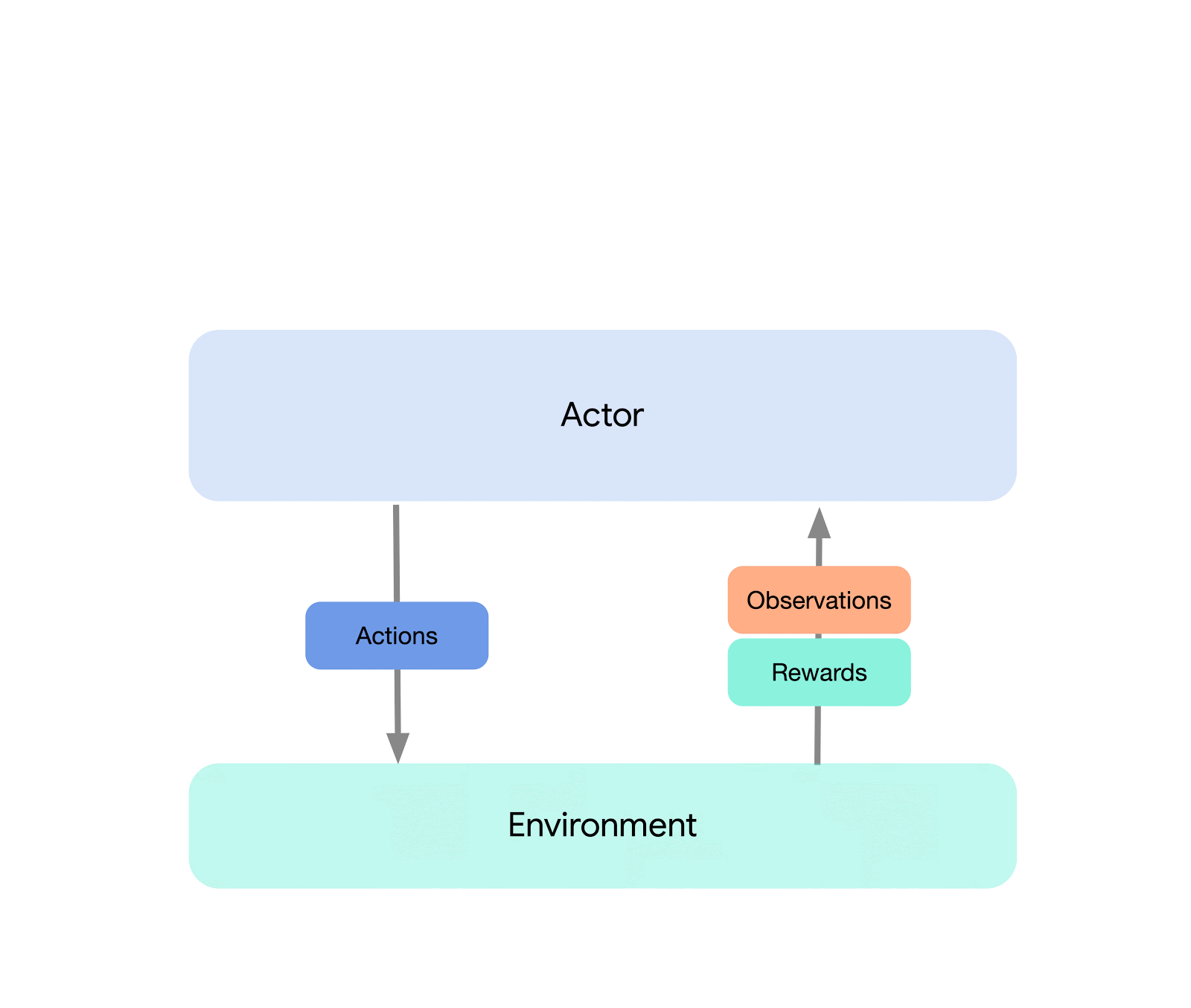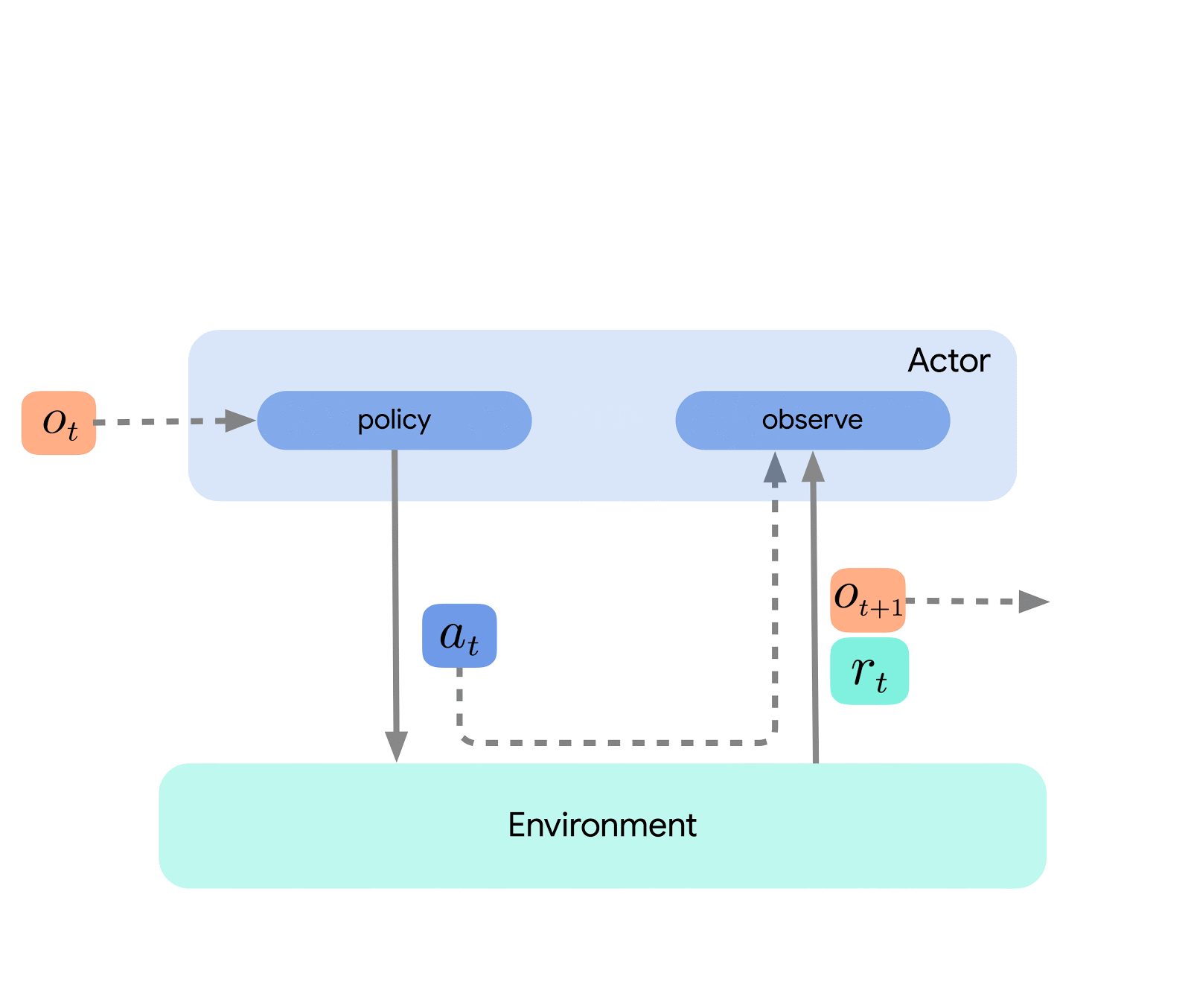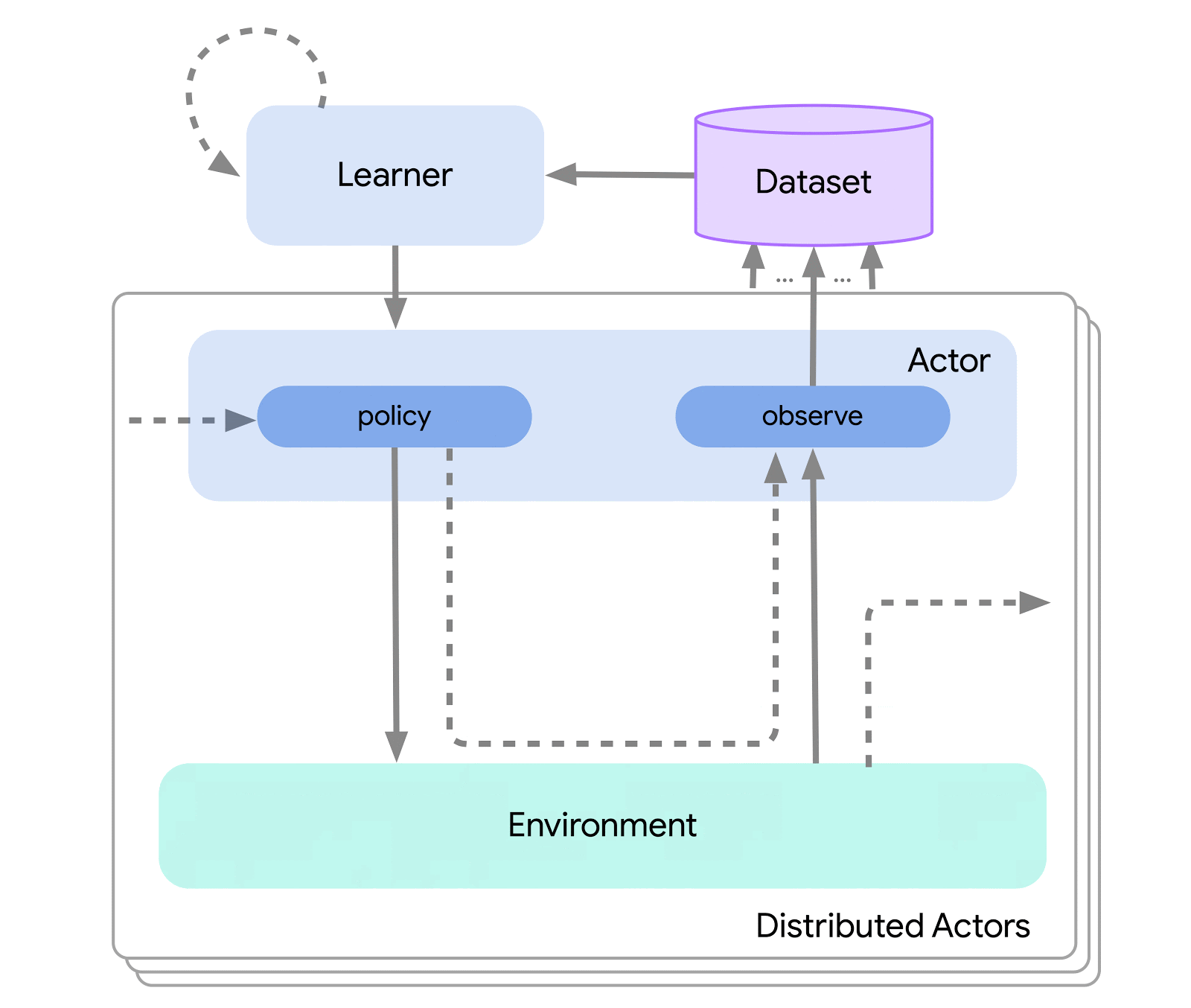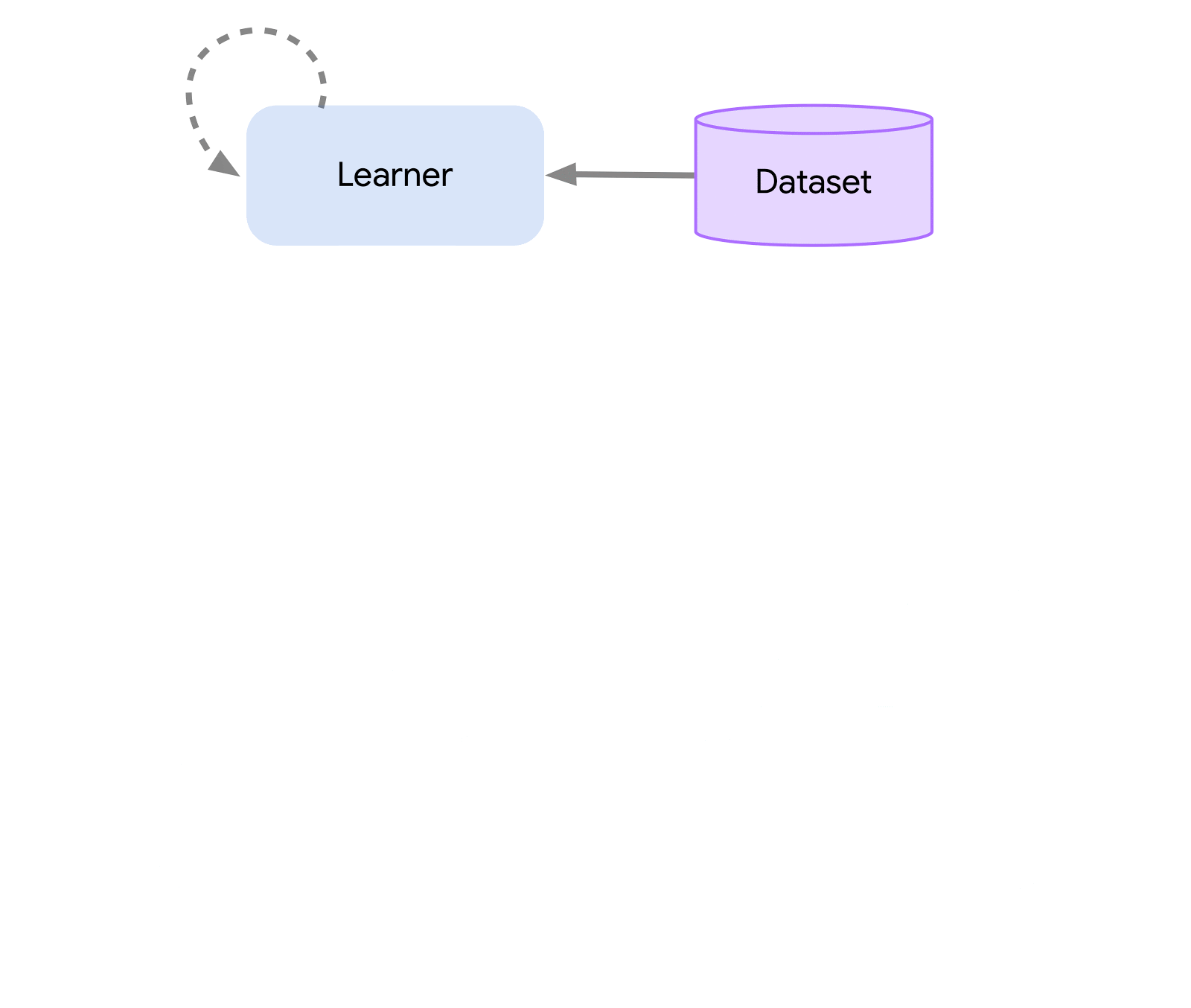
Cette conception nous permet de créer, tester et déboguer facilement de nouveaux opérateurs dans des scénarios à petite échelle avant de les mettre à l’échelle, tout en utilisant la même représentation et le même code d’apprentissage. Acme fournit également un certain nombre d’utilitaires utiles allant des points de contrôle aux instantanés en passant par les aides arithmétiques de bas niveau. Ces outils sont souvent les héros méconnus de tout algorithme RL, et chez Acme, nous nous efforçons de le garder aussi simple et compréhensible que possible.
Pour permettre cette conception, Acme utilise également Reverb : un nouveau système d’entreposage de données efficace conçu pour les données d’apprentissage automatique (et d’apprentissage par renforcement). La réverbération est principalement utilisée comme système de relecture d’expériences dans les algorithmes d’apprentissage par renforcement distribué, mais elle prend également en charge d’autres représentations de structure de données telles que FIFO et les files d’attente prioritaires. Cela nous permet d’utiliser de manière transparente des algorithmes dans et hors de la politique. Acme et Reverb ont été conçus dès le départ pour bien jouer l’un avec l’autre, mais Reverb est entièrement utilisable seul, alors jetez-y un coup d’œil !
Parallèlement à notre infrastructure, nous publions également des instanciations à processus unique pour un certain nombre d’agents que nous avons créés avec Acme. Cette série fonctionne à partir du contrôle continu (D4PG, MPO, etc.), du Q-learning discret (DQN et R2D2), et plus encore. Avec des changements minimes – en divisant les frontières représentation/apprentissage – nous pouvons exécuter les mêmes facteurs de manière distribuée. Notre première édition se concentre sur les facteurs à processus unique, car ils sont principalement utilisés par les étudiants et les praticiens de la recherche.
Nous avons également soigneusement mesuré les performances de ces clients sur un certain nombre d’environnements, à savoir control suite, Atari et bsuite.
Une liste de lecture de vidéos montrant des agents formés à l’aide du framework Acme
Bien que des résultats supplémentaires soient facilement disponibles dans notre article, nous montrons quelques graphiques qui comparent les performances d’un seul opérateur (D4PG) lorsqu’elles sont mesurées à la fois par rapport aux étapes de l’acteur et au temps de l’horloge murale pour une tâche de contrôle continu. En raison de la façon dont nous limitons le taux d’entrée de données en relecture – reportez-vous à l’article pour une discussion plus approfondie – nous pouvons voir à peu près les mêmes performances en comparant les récompenses reçues par l’agent au nombre d’interactions qu’il a avec le environnement (étapes d’acteur). Cependant, à mesure que l’agent devient plus parallèle, nous constatons des gains en termes de rapidité d’apprentissage de l’agent. Dans des domaines relativement petits, où les observations sont limitées à de petites zones de caractéristiques, même une augmentation modeste de ce parallélisme (4 acteurs) se traduit par un facteur qui prend moins de la moitié du temps pour apprendre la politique optimale :

Mais pour des domaines plus complexes où les observations sont des images relativement coûteuses à générer, on constate des gains plus complets :

Les gains pourraient être encore plus importants dans des domaines tels que les jeux Atari où les données sont plus coûteuses à collecter et les processus d’apprentissage prennent généralement plus de temps. Cependant, il est important de noter que ces résultats partagent le même code de représentation et d’apprentissage entre la configuration distribuée et non distribuée. Il est donc tout à fait possible d’expérimenter ces facteurs et ces résultats à plus petite échelle – en fait, c’est quelque chose que nous faisons tout le temps lorsque nous développons de nouveaux agents !
Pour une description plus détaillée de cette conception, ainsi que plus de résultats pour nos proxys de base, consultez notre article. Ou mieux encore, jetez un œil à notre référentiel GitHub pour voir comment vous pouvez commencer à utiliser Acme pour simplifier vos clients !